Vécolo
Projet d'étude :
Conception et développement d'un service de location de vélo électrique rechargé uniquement
grâce à une énergie renouvelable. Plusieurs bornes sont réparties dans la ville de Paris.
Code source : https://github.com/vecolo-project
- Présentation de vécolo
- Déploiement continu et architecture serveur
- VéAPI
- Végular
- Vékanban
- Vémock
- VéScrapper
Présentation de vécolo
I. Introduction
1. Problématique
Aujourd'hui, la technologie nous facilite la vie de tous les jours. Par exemple, les moyens de transport sont de plus en plus diversifiés et toujours plus optimisés pour le développement durable afin de toucher le plus de personnes possible. Des services existent même pour permettre aux usagers de bénéficier par exemple d'un vélo partout dans une ville afin de se déplacer librement (Vélib).
Mais ces vélos ne sont pas adaptés pour tout le monde (personnes âgées ou peu endurantes ...) et depuis peu, ces services proposent également la location de vélos électrique. Ces vélos sont rechargés à l'aide de bornes dispersées dans la ville et sur lesquels les vélos doivent être rendu après un trajet. Seulement l'énergie utilisée pour recharger les vélos n'est pas toujours très
écologique, ce qui vient casser le concept de base qui était de proposer à une ville un moyen de locomotion en libre-service et vert.
2. Solution
L'entreprise Vécolo propose un service de location de vélo électrique rechargé uniquement grâce à une énergie renouvelable. Plusieurs bornes sont réparties dans la ville de Paris. Elles sont équipées d'un panneau solaire, d'une éolienne à axe verticale ainsi que d'une batterie pour stocker l’énergie si aucun vélo n'est à recharger.
La borne sera composée d’un abri où les gens vont et viennent, déposant leurs vélos, les laissant recharger et les reprennent. La borne de recharge partage l’énergie entre les différents vélos en cours de rechargement. L'emplacement sera conçu pour être entièrement autonome.
Le chiffre d’affaires de l'entreprise se fera par des abonnements ainsi que des partenariats. Plusieurs forfaits seront disponibles en fonction du besoin de la personne. L'entreprise devra s'assurer de l'achat et la maintenance des vélos.
3. Etudiants ayant participés
Noé LARRIEU-LACOSTE
Je m’appelle Noé LARRIEU-LACOSTE, actuellement en 3ᵉ année à l’ESGI, j’ai également effectué mes deux premières années dans cette école. Cela m’a permis de me familiariser avec beaucoup de langes de programmation et technologies à travers plusieurs projets.
Le projet demandé étant un sujet libre, nous avons été très ambitieux sur le travail à réaliser, mais c’est l’occasion pour nous de montrer ce dont nous sommes capables de faire après 3 ans d’études. Il y a beaucoup d'aspects extrêmement intéressants dans ce projet que nous avons envie de développer et même si nous ne savons pas tout de suite comment les faire, nous avons hâte d'apprendre et d'aboutir à quelque chose de grand qui marquera.
Swann HERRERA
Je suis un jeune développeur qui travaille en alternance dans une petite agence de communication. J’ai fait mes deux premières années de formation théoriques à l'ESGI. Cette collaboration avec Noé n’est pas la première, en effet, nous avons déjà eu le plaisir de mener à bien d’autres projets.
Mon partenariat avec Clément est plus récent, bien que nous nous connaissions depuis notre première année à l’ESGI. Néanmoins, je qualifierai notre entente, depuis cette date, comme très bonne.
Au début de ce projet, j'avais une certaine appréhension à propos d'Angular, n'en ayant jamais fait auparavant, même si je suis plutôt habitué au framework frontend. La partie java et la partie micro-langage avaient aussi une position particulière, puisque pas vraiment en lien avec le projet de départ.
II. Focus sur LES APPLICATIONS
Sans compter la partie sur l’intégration serveurs, 5 applications ont été développées pour ce projet.
1. Vegular (front-Office)
Une application web a été développé pour permettre aux administrateurs comme les clients d'utiliser le service Vécolo.
Cette application a été développée à l'aide du framework Angular, développé par Google.

Répartition et charge de travail
Ce projet a été fait côte à côte entre Noé et Swann.
Liste non exhaustives des tâches effectuées :
• Export PDF (Noé)
• Gestion des trajets (Noé)
• Mise en place de l’architecture de l’application et du DataStore (Noé)
• Création des composants partagée (Noé & Swann)
• Gestion des utilisateurs (Swann)
• Gestion des stations (Noé)
• Gestion des abonnements (Noé & Swann)
• Gestion des vélos (Swann)
• Carte interactive (Noé)
• Page d’accueil & formulaire de contact (Swann)
• Statistiques (Noé)
• Upload de fichiers (Swann)
2. VeAPI (Back-Office)
Afin que notre application web puisse correctement communiquer avec notre base de données et les différents services, une API a été développée en NodeJS. Celle-ci sert notamment d'interface avec la base de données.
Répartition et charge de travail
Ce projet a été initié par Swann et Clément. Clément a commencé à travailler principalement sur les routes et services jusqu’à son départ. L’application a ensuite été reprise en main par Noé et Swann.
Liste non exhaustives des tâches effectuées :
• Gestion des factures (Noé)
• Envoie de mails (Noé)
• Routines (Noé)
• Authentification (Swann)
• Seeds (Noé & Swann)
• Architecture de l’application (Swann)
• Modèles et services initiaux (Swann & Clément)
• Création des migrations pour la base (Swann)
• Servies initiales (Swann & Clément)
• Upload de fichiers (Swann)
3. Vekanban (Application Java)
Afin d'avoir une gestion de projet agile, nous avons développé une application Java de type kanban dans le but de pouvoir répartir les tâches au sein de l'équipe de développement.
Répartition et charge de travail
Ce projet a été essentiellement réalisé par Noé, car plus à l’aise avec les technologies utilisées et le soutien de Swann.
Liste non exhaustives des tâches effectuées :
• Fusion de Java FX et Spring (Noé)
• Log4J (Noé & Swann)
• Intégration des services (Swann)
• Gestion des labels FX (Noé)
• Gestion des projets FX (Noé)
• Gestion des taches FX (Noé)
• Gestion du compte FX (Noé)
• Markdown FX (Noé)
• Plugin (Noé)
4. Vemock (Mockage des stations)
Puisque la mairie de Paris n'a pas souhaité nous financez pour mettre à disposition des stations dans la ville, il a fallu les simuler nous-mêmes pour avoir un comportement cohérent sur le site.
Nous avons développé Vemock pour répondre à ce besoin et simuler le comportement d'une station complètement autonome.
Répartition et charge de travail
Ce projet a été réalisé par Noé, car c’était lui qui possédait le Raspberry et avait une bonne idée, déjà de quoi faire.
5. Vescrapper (Langage de programmation)
Vescrapper est un langage de programmation que nous avons développé afin d’effectuer des recherches avancées sur internet pour trouver des références et des images de vélo pour pouvoir trouver les revendeurs et alimenter Vécolo à vélo
Répartition et charge de travail
Ce projet a été réalisé par Noé et Swann.
Liste non exhaustives des tâches effectuées :
• Grammaire du langage (Noé & Swann)
• Reduction du langage (Noé & Swann)
• Menu CLI (Swann)
• Construction des requêtes google (Noé)
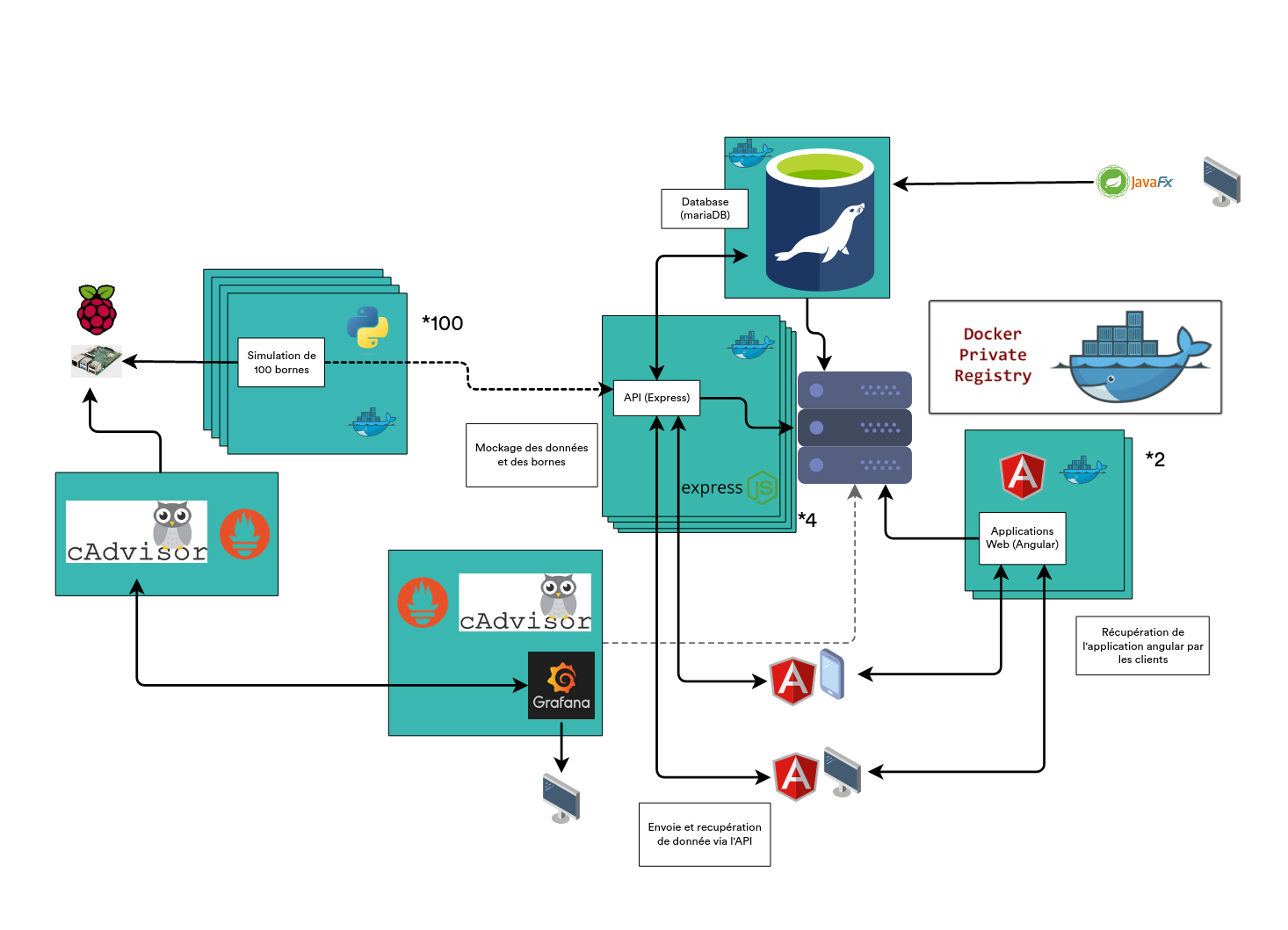
6. Architecture serveur
Ce projet a une partie serveur assez poussé, puisqu'elle regroupe beaucoup d'applications qui sont gérées grâce à docker ainsi que de la réplication dans des clusters.
Voici le schéma final de notre architecture logicielle
IIII. Bilan du projet
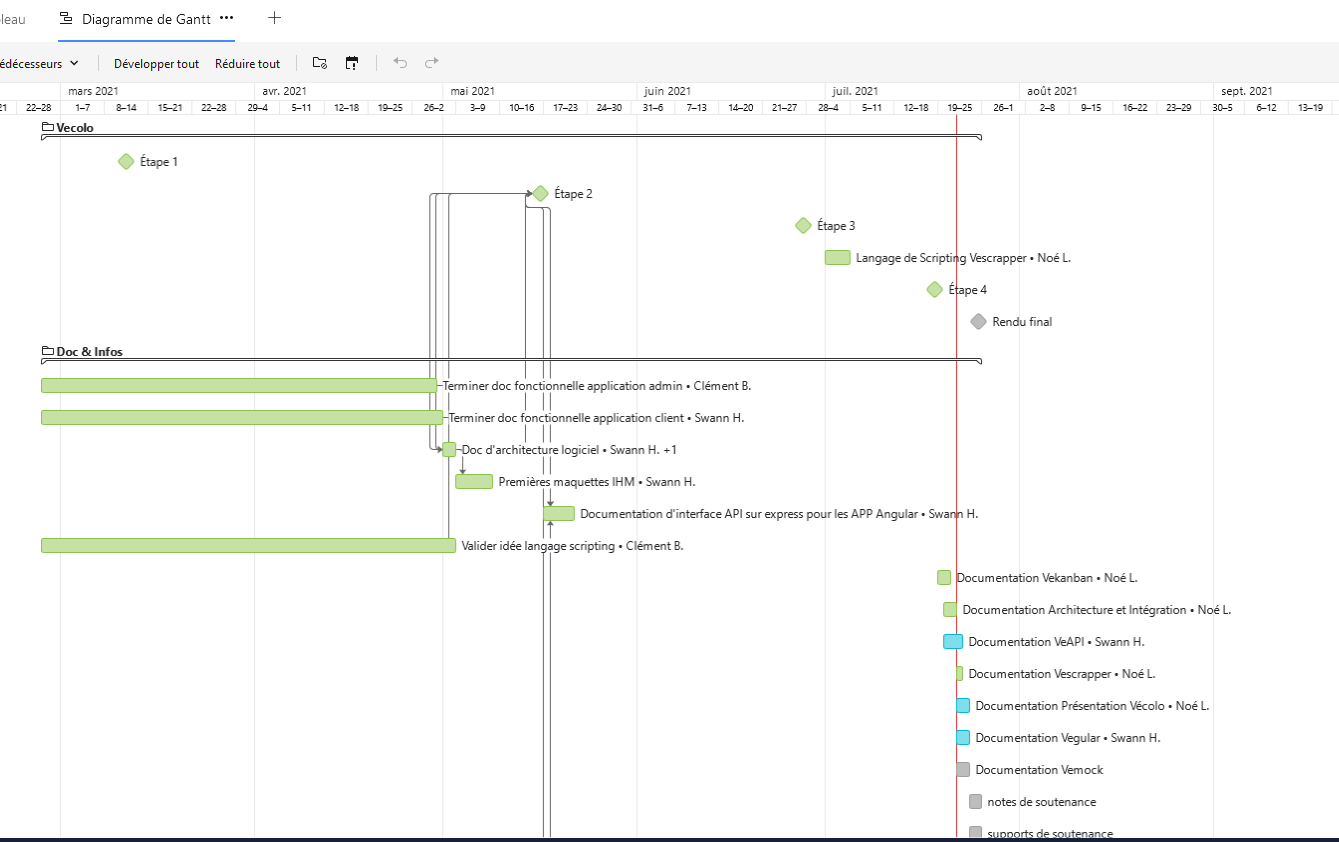
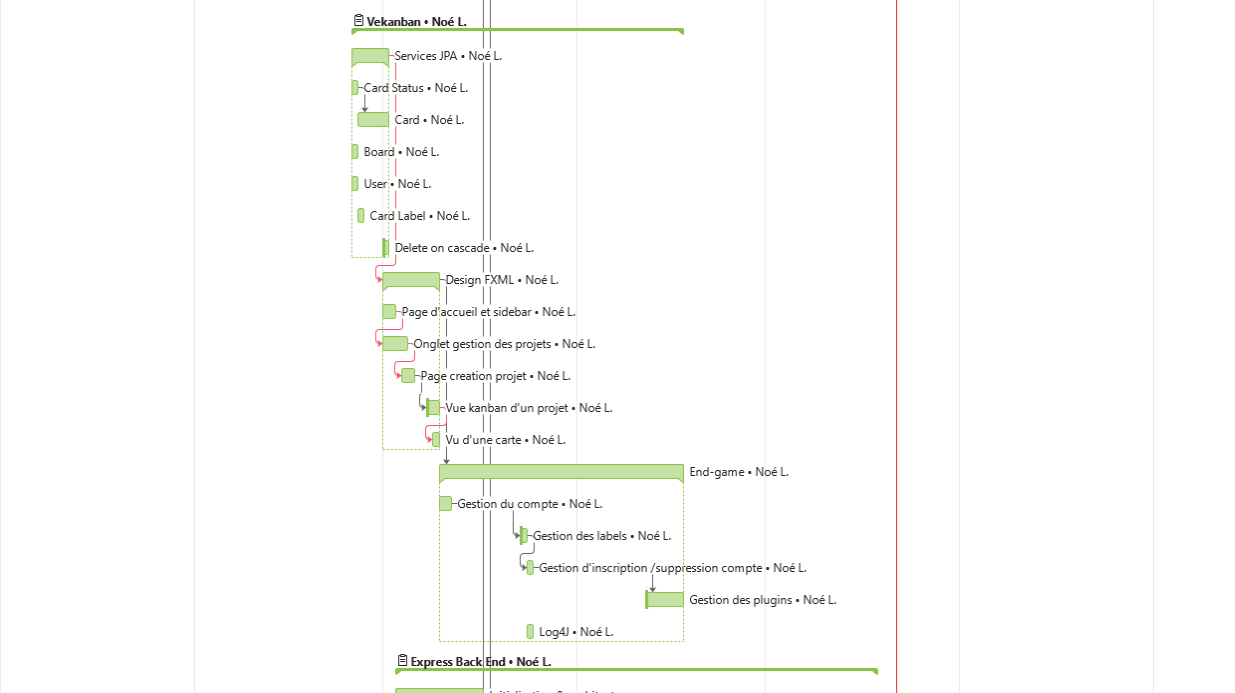
1. Organisation du projet
Pour la réalisation de ce projet, nous avons tenu un jour dans l'équipe un diagramme de Gantt sur les différentes tâches à faire au sein des différents projets. Nous vous invitons à le consulter pour constater la répartition des tâches entre les membres du groupe.
2. Points non résolus
Simulation de trajets à vélo
Au départ, nous souhaitions, au même titre que nous 6 millions les stations, simuler des trajets à vélo en temps réel.
Cela impliquait de mettre en place un système de path finding entre 2 stations, mais également de la localisation en temps réel et du stockage de données temporaires.
Cela était trop complexe à faire et par manque de temps, nous n'avons pas développé cette fonctionnalité.
3. Appreciation individuelle
Noé LARRIEU-LACOSTE
Ce projet a été un véritable défi, de plus un de nos confrères nous a quitté en cours de route ce qui nous a demandé d'en fournir 2 fois plus pour terminer ce projet si ambitieux.
Je suis extrêmement fière du résultat, quand même si nous avons dû faire quelques concessions à certains endroits, nous sommes allés beaucoup plus loin dans d'autres aspects du projet, je trouve le résultat extrêmement convaincant.
C’est sans doute le projet le plus gros que j'ai eu à réaliser jusqu’à maintenant, j'ai appris énormément en le faisant.
Je pense que nous sommes allés au-delà de ce qui était attendu.
Swann HERRERA
Aujourd'hui, quelques jours avant la fin du projet, je suis très fier du travail qui a été accompli et de l'architecture qui a été mise en place. Je suis aussi soulagé d'arriver à la fin.
Même si certaines choses n'ont pu aboutir, je considère que les éléments qui ont été réalisés, ont été bien réalisés.
Ma principale déception se situe sur le fait qu’un des membres de notre groupe n’ait pas continué cette collaboration. Ma déception n’est pas spécialement en lien avec le travail que cela a induit. Ma déception est plus en lien avec le fait qu’il n’aura pas pu partager le goût de la réussite, quel qu’en soit son degré.
Déploiement continu et architecture serveur
I. Introduction
1. Ressources utilisés
Organisation Github
Afin de gérer au mieux les différents projets que nous avions à réaliser, nous avons créé une organisation sur Github afin de regrouper tous les projets à un seul endroit. L’organisation s'appelle Vécolo Project https://github.com/vecolo-project
Serveur VPS
L'intégralité de nos applications et base de données sont hébergées sur un serveur VPS sur lequel pointe le domaine vecolo.fr
Le serveur possède 2 processeurs virtuels cadencés à 2.60 GHz, 2go de RAM, 30go d’espace de stockage en RAID10 ainsi qu’un connexion internet de 100 Mbps.
Raspberry PI 4
Nous avons un besoin spécifique qui est que nous devons simuler des station de recharge de vélo un peu partout dans Paris. Pour ce faire nous utilisons une Raspberry PI 4 car celle-ci possède un processeur ARM, c'est ce qui se rapproche le plus du futur composant embarqué sur de vraies stations de recharge.
Elle embarque un processeur ARM 4 cœurs 64bits cadencés à 1.5 GHz, 4go de RAM et 32go d’espace de stockage.
Nous possédons physiquement cette Raspberry et elle est hébergé physiquement chez nous.
2. Technologies phares
Docker Swarm & Portainer
Docker est un outil qui peut empaqueter une application et ses dépendances dans un conteneur isolé, qui pourra être exécuté sur n'importe quel serveur. Cela est très utile pour déployer et maintenir des applications sur un serveur sans conflits de dépendances.
Portainer est une interface web permettant d’avoir une meilleure gestion de docker sur un serveur, cela permet d’administrer toute nos instances sans avoir à utiliser un terminal.
Registre Docker privé
Un registre docker est un espace de stockage où mettons à dispositions les images docker de nos différentes application. Le fait qu’il soit privé signifie qu’il n’est pas accessible publiquement et peut être auto hébergé.
MariaDB
MariaDB est un système de gestion de base de données. Il s'agit d'un fork communautaire de MySQL. C’est dans cette base de données que nous stockons toute les données relative à Vécolo, le monitoring des applications et le Schéma BDD de l’application Java Vekanban.
Grafana
Grafana est un logiciel libre qui permet la visualisation de données. Il permet de réaliser des tableaux de bords et des graphiques principalement depuis des bases de données temporelles. Il est très souvent utilisé pour faire du monitoring d’applications serveurs.
Github Actions
Les actions Github sont des procédures automatiques qui peuvent être lancés lorsque différentes actions sont lancées sur un dépôt Github (push, merge, pull request, …). Elles permettent de lancer différentes actions en relation avec le code (exécution des tests unitaires, compilation de l’application, notifications via webhooks, …) ;
Caddy
Caddy est un serveur web écrit en G. Il a été conçu à l’ère du web sécurisé et il fonctionne ainsi par défaut et fourni du https, sauf si c’est demandé explicitement de ne pas le faire.
Il se chargera tout seul d’obtenir un certificat Let’s Encrypt et de le renouveler ensuite sans intervention manuelle. Il se chargera aussi de rediriger toutes les requêtes vers l’adresse en https, là encore sans configuration spécifique.
3. Architecture Globale
Voici le schéma d'architecture globale de notre projet que nous allons détailler dans ce rapport :
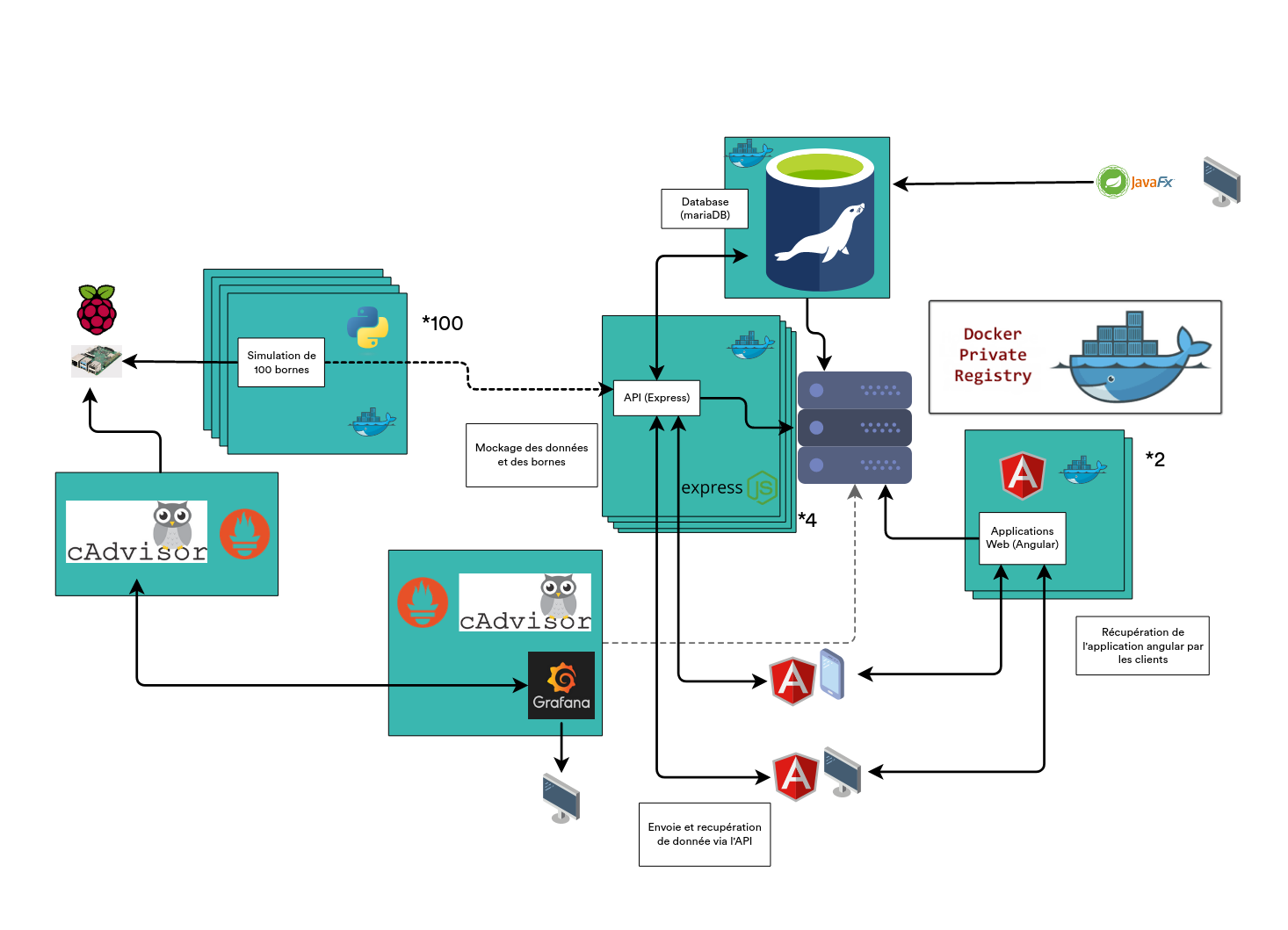
II. Docker, le cœur de notre architecture
Pour ce projet, nous avons vraiment voulu exploiter docker avec ce qu'il pouvait faire de mieux. Nous avons donc passé énormément de temps à apprendre cette technologie et l'implémenter correctement au sein de notre projet.
1. Tout est docker
Dockerisation de tous les applicatifs
Dans d'autres projets, mise à part l'application client Java, toutes nos applications possède un Dockerfile personnalisé qui permet à celle-ci de se lancer dans un container sans contraintes.
Cela nous permet d'avoir des images clé en main directement instanciable et fonctionnel.
Voici par exemple Dockerfile de notre serveur backend API.
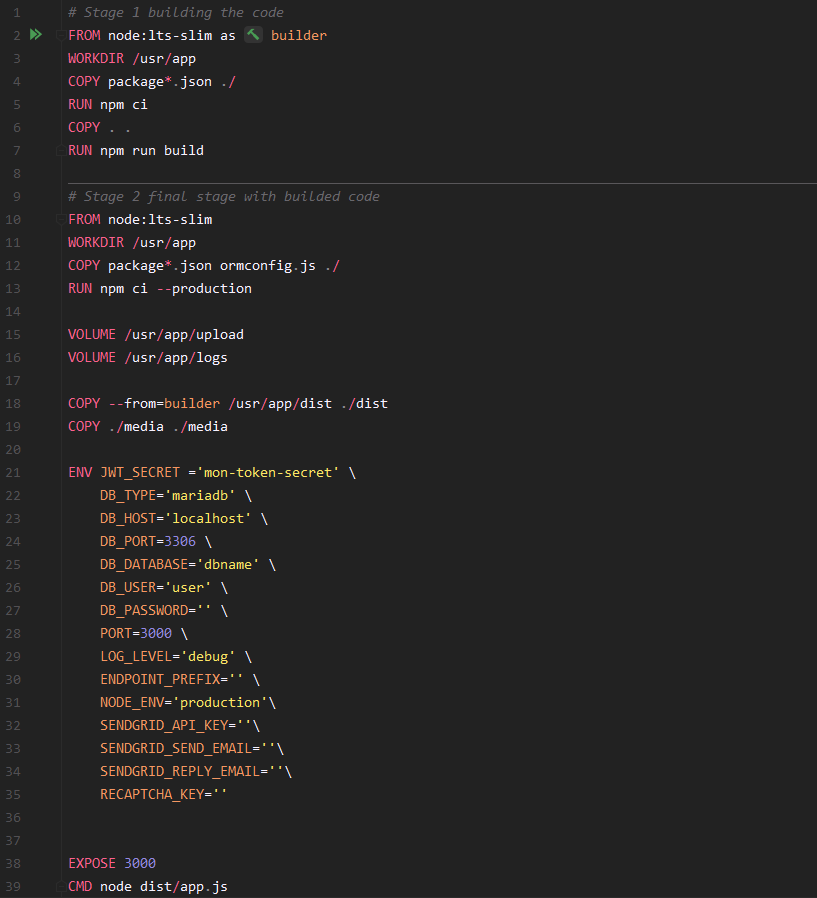
Afin que l'image finale soit la plus légère et performante possible, et qu’elle ne possède que l'applicatif, nous possédons dans nos instructions une image intermédiaire qui va simplement se contenter de compiler notre code avant de le faire transiter dans l'image finale qui possédera l'exécutable uniquement.
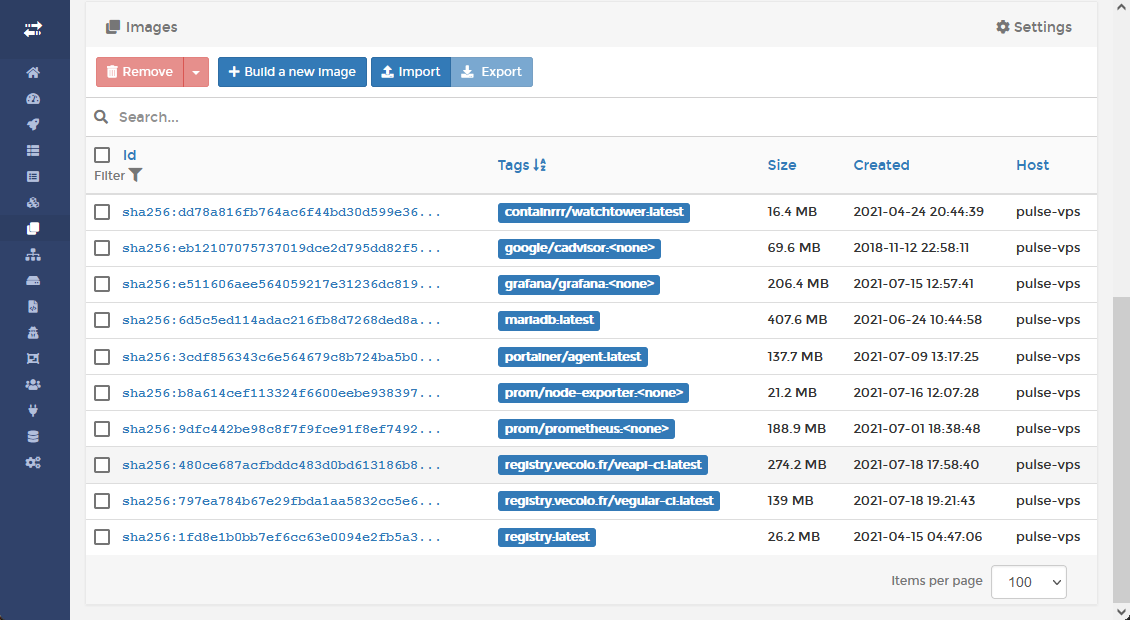
Portainer, l’interface de contrôle
Grâce à Portainer, nous possédons une interface web pour administrer nos images docker ainsi que les containers lancés. Un agent Portainer est présent aussi bien sur le serveur VPS que sur la Raspberry mais c'est le serveur VPS qui héberge l'interface web.
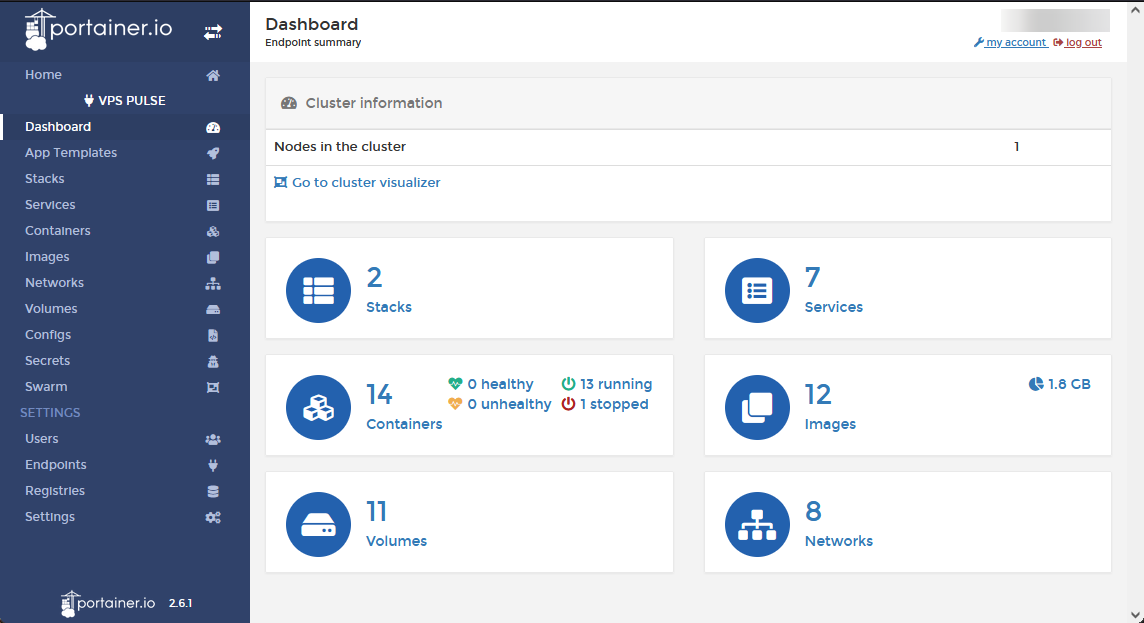 |
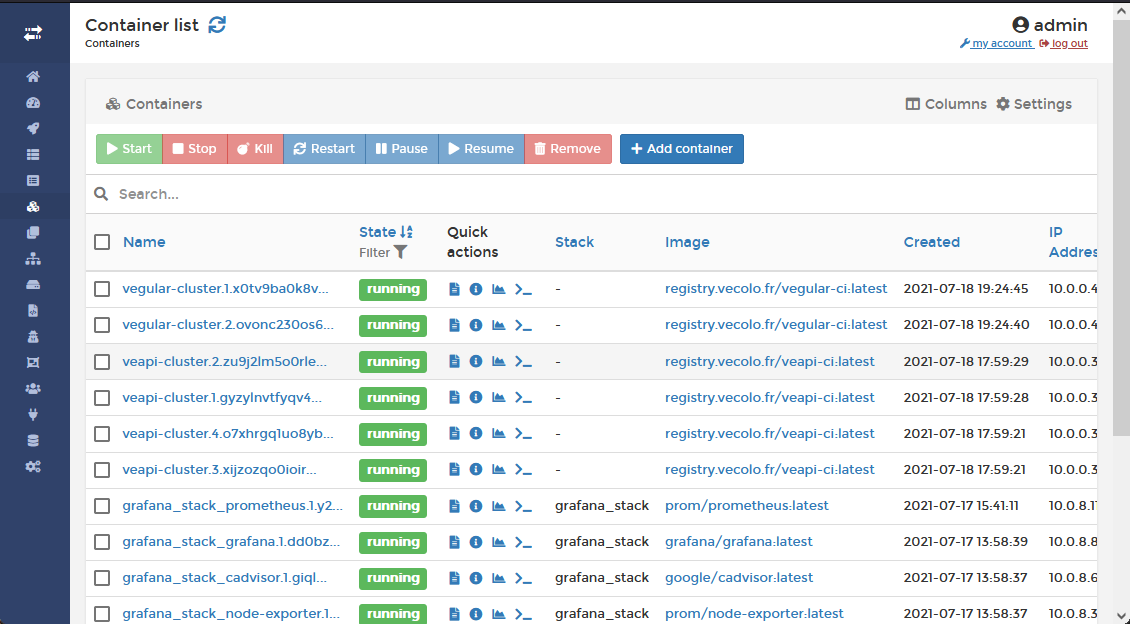 |
 |
 |
2. Cluster et load balancer
Nous avons décidé d'intégrer à notre projet la problématique de performance de notre application lorsque celle-ci est et soumis à une forte charge. Heureusement, docker nous propose plusieurs solutions pour répondre à cette problématique.
Docker Swarm
Docker-Swarm est un outil conçu pour enrichir Docker lui offre un “mode Swarm”. Ce mode donne la possibilité de créer des clusters de machines exécutants des conteneurs Docker, qui fonctionnent ensemble comme une seule machine.
Docker-Swarm permet entre autres de :
· Coordonner les conteneurs et de leur affecter des tâches à chacun d’eux.
· Gérer et suivre l’état des différents conteneurs dans le cluster, et redistribuer les tâches en cas de besoins.
· Assurer la scalabilité et flexibilité de l’infrastructure, en augmentant ou diminuant le nombre de clusters mis en services.
· Gérer et mettre à jour les applications sur plusieurs conteneurs.
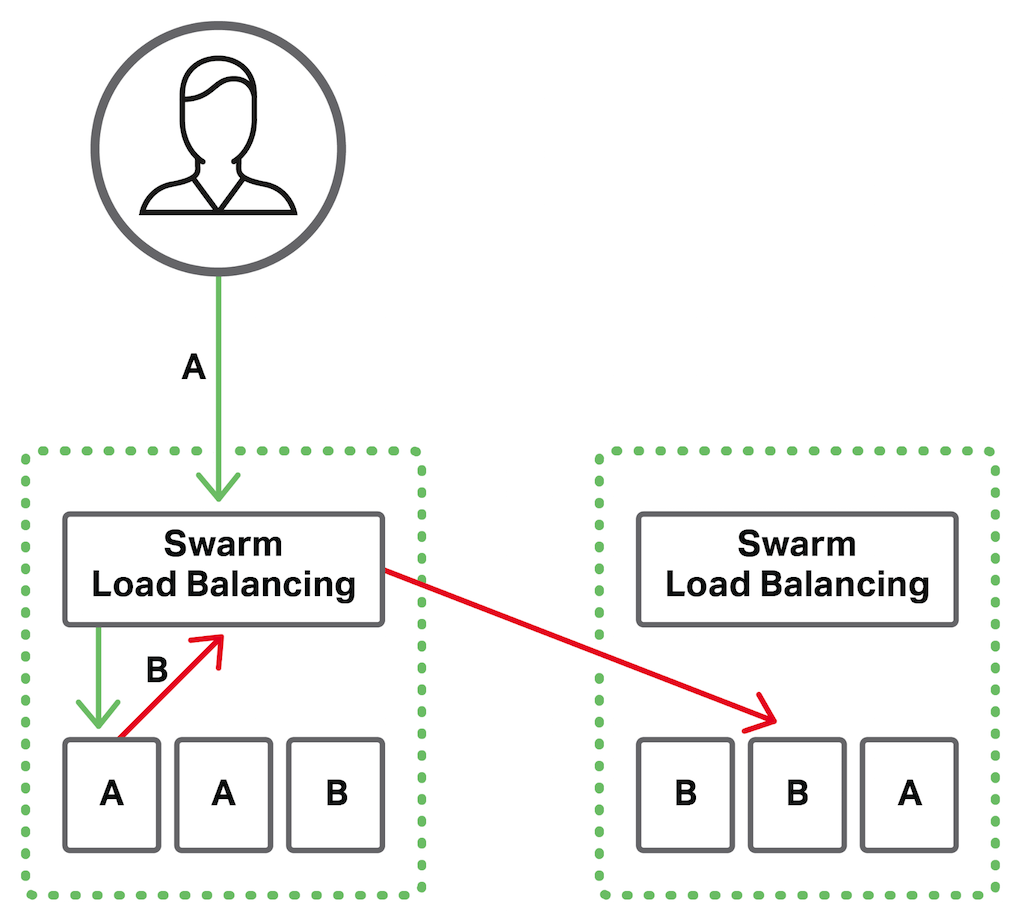
Mise en place des services
Swarm fonctionne grâce aux services, qui sont des descriptions de l’état qu’on souhaite garder pour les nœuds du cluster. Pour fonctionner, un service a besoin d’un conteneur et de commandes à exécuter sur celui-ci.
Les services exécutés sur Swarm peuvent avoir plusieurs caractéristiques, telles que :
· Options des services : lors de la création du service, on peut configurer plusieurs paramètres selon les besoins de nos applications (limites mémoire, le nombre des répliques de l’image à exécuter sur Swarm, etc.).
· État désiré : le déploiement du service permet de définir l’état désiré sur le Swarm. L’état désiré représente le comportement normal ou la configuration idéale de l’application sur Swarm. Par exemple, lorsqu’un problème survient et met à défaut l’état désiré, les “Manager Nodes” interviennent pour corriger le problème en affectant plus de ressources au service.
Grâce aux services, nous pouvons créer un répartiteur de charge entre plusieurs instance d’une même application. Celui-ci sera répliqué autant de fois que voulu.
Dans le cas de notre application, nous possédons un service sur le backend API qui va faire fonctionner 4 instances de notre application et répartir la charge équitablement sur chaque nœuds. Notre application WEB elle, possède un service avec 2 instances.


3. Registre docker privé
Les applicatifs étant la propriété de Vécolo, nous ne pouvons pas les héberger publiquement sur docker hub. Il nous faut notre propre registre, le VPS possède donc un registre docker privé avec une authentification. C'est sur ce registre que nous poussons les images de nos applicatifs. Nous avons ainsi un contrôle total sur l’hébergement de nos images Docker.
III. Déploiement continu
Les étapes de déploiement d'un projet web sont souvent fastidieuses et répétitif. De plus, il faut parfois que cela se fasse rapidement et il n'y a pas toujours quelqu'un de disponible pour le faire.
Nous avons donc fait en sorte que à partir du moment où nous poussons du code sur des branches spécifiques de nos projets, l'application soit automatiquement mise à jour sur le serveur principal sans intervention de notre part.
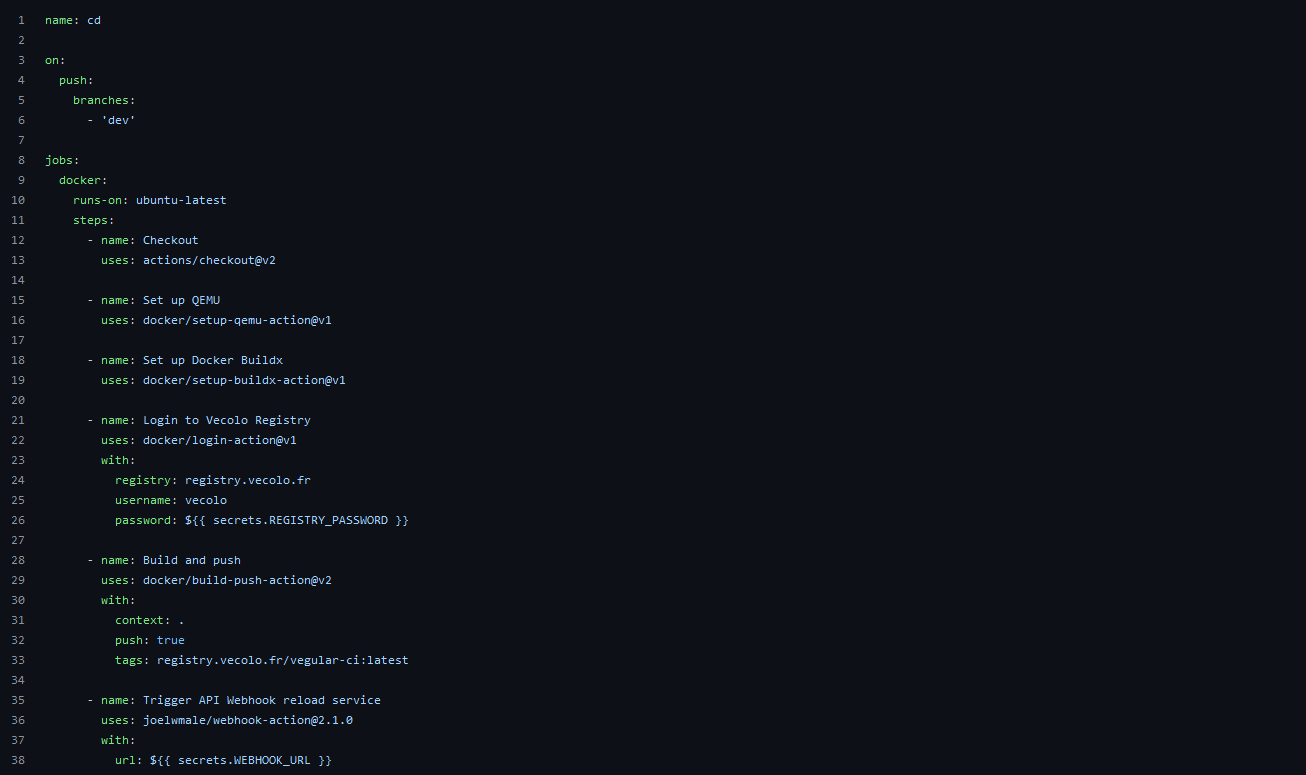
1. Builds automatique & Webhooks
Grâce aux actions Github, nous avons pu mettre en place sur nos dépôts de l’application Backend API et Front end Angular des évènements déclenchés lorsque la branche « dev » est mis à jour (dernière version fonctionnelle de nos applicatifs). Cet évènement va se charger de construire l’image Docker associé à la dernière version du projet, avant de l’envoyer à notre registre privé.
Une fois cela fait avec succès, un signal est envoyé au service (API ou Angular) présent sur le serveur à l’aide d’un Webhook.
2. Mise à jour des services incrémental
Grâce à la configuration de nos service, celui-ci met à disposition une URL pouvant être appelé depuis un Webhook. Quand celle-ci est requêté, le service sait qu’il doit redémarrer en mettant à jour l’image Docker de ses instances.
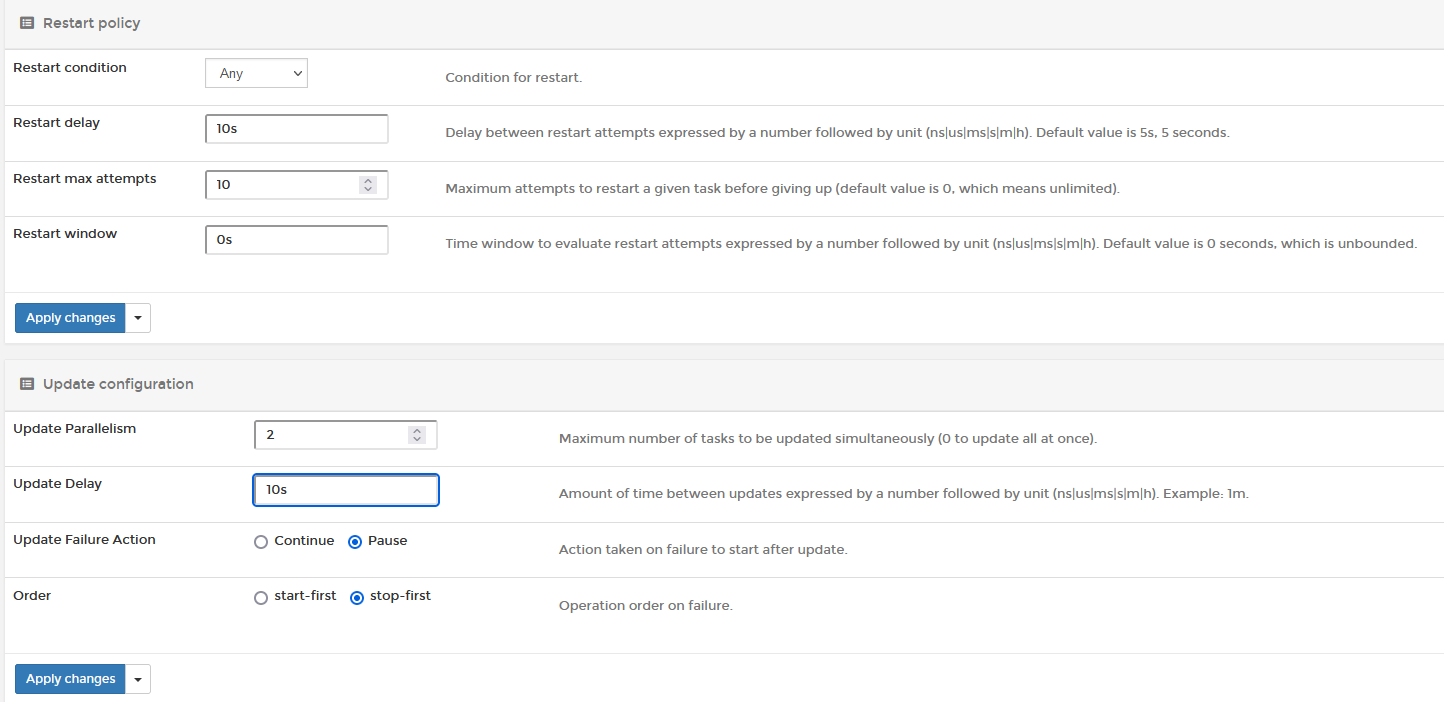
Cependant nous ne voulons pas d'interruption de service. C'est pourquoi les instances ne se mettent pas toutes à jour en même temps.
Dans le cadre du back end API (4 instances) les serveurs se mettent à jour 2 par 2. Les 2 derniers serveurs ne se mettent à jour que si les 2 premiers ont réussi à se lancer correctement et continue de tourner depuis au moins 10 secondes.
Pour l'application Angular qui ne contient que 2 instances le service va les mettre à jour une par une
En cas d'échec, le service va retenter plusieurs fois de lancer les instances jusqu’à un maximum de 10 fois. Si au bout de 10 fois le service n'arrive toujours pas à lancer les instances, il effectue un rollback sur les précédentes versions fonctionnelles de l'application. Ainsi, avons en permanence une instance fonctionnelle de lancée.
IV. Raspberry VS 100 Bornes
1. Objectif recherché
Notre projet Vemock consiste à simuler le comportement d'une station. Or dans notre application, nous souhaitons avoir bien plus qu'une seule station d'active afin que le comportement soit réaliste. De plus, nous souhaitons simuler ce comportement depuis un appareil ayant des composants matériels prévus pour de l'embarqué. Cela permettra dans le futur une meilleure compatibilité sur de vrais stations.
Le choix de la Raspberry était donc tout indiqué. Il fallait maintenant trouver un moyen correct de faire tourner plusieurs instance de station différente sur cette Raspberry.
2. Stack de 100 bornes
Docker Compose est un outil qui permet de décrire (dans un fichier YAML) et gérer (en ligne de commande) plusieurs conteneurs. Il est alors possible de démarrer un ensemble de conteneurs en une seule commande. Dans le fichier docker-compose.yml, chaque conteneur est décrit avec un ensemble de paramètres qui correspondent aux options disponibles lorsqu'on lance une instance normalement.
La solution d'utiliser docker compose pour monter plusieurs bornes en même temps était donc très intéressante.
Notre docker-compose final permet de lever en une seule commande 100 instances ! elles sont toutes identifiées sur l'API grâce à un token unique et permet donc de simuler le comportement de 100 stations à Paris.
 |
 |
3. Générateur du docker-compose
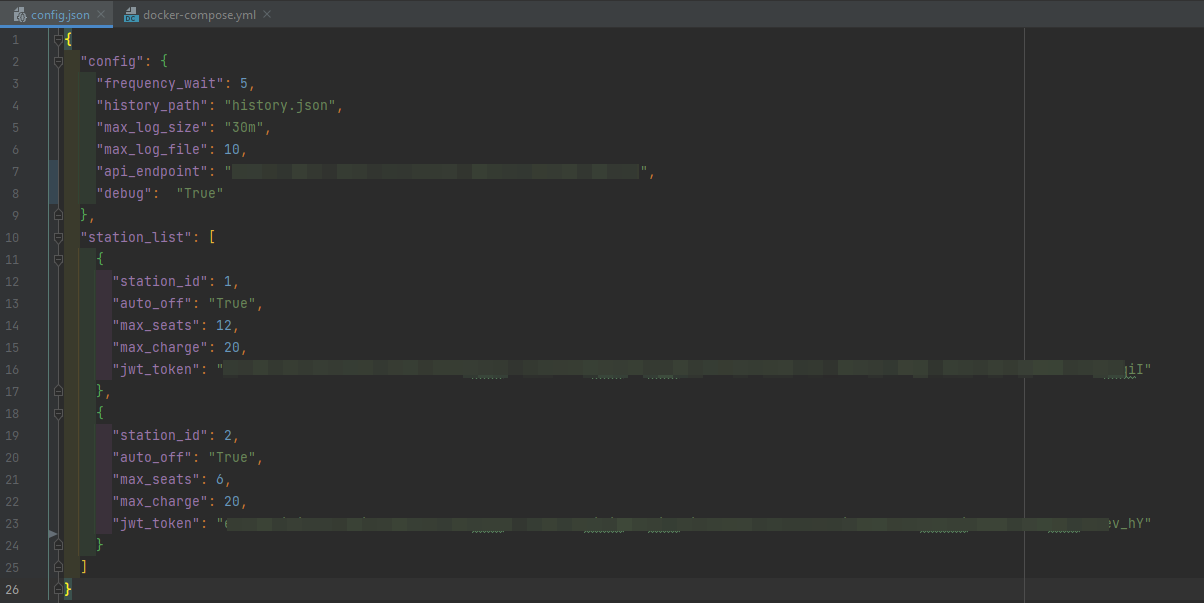
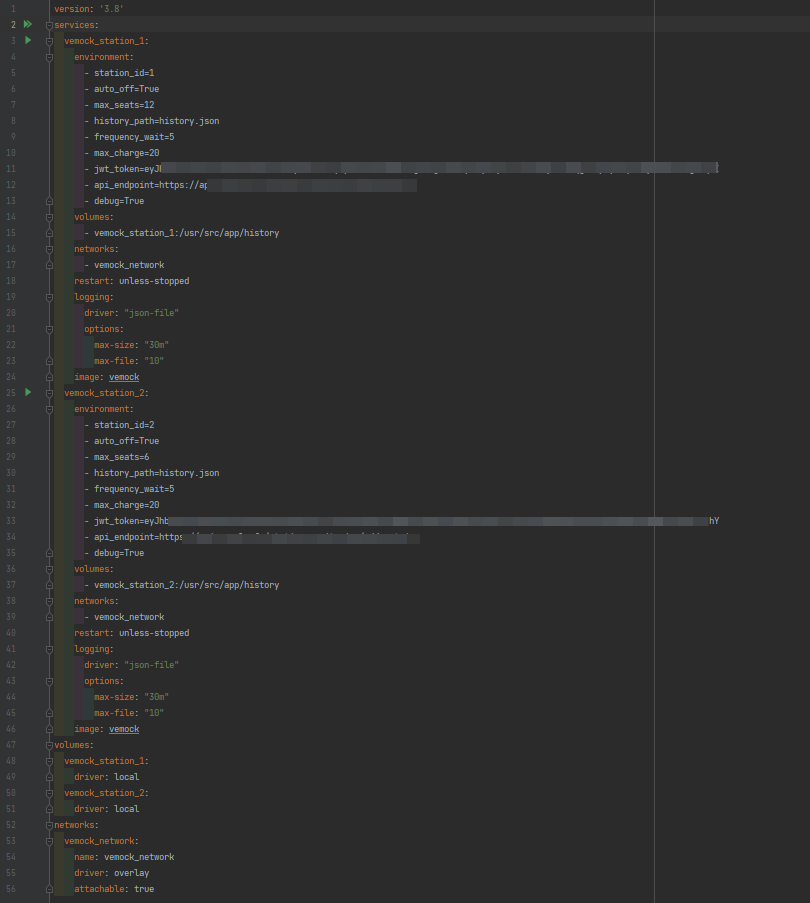
Pour simuler le comportement de 100 stations, le fichier docker compose docker-compose.yml fais plus de 2400 lignes. Bien sûr il serait trop long d'écrire toutes ces lignes à la main…
Nous avons donc mis au point un script python qui permet à partir d'un fichier de configuration JSON beaucoup moins gros de générer notre docker-compose.yml final.
Voici un exemple des fichiers de configuration avec seulement 2 stations :
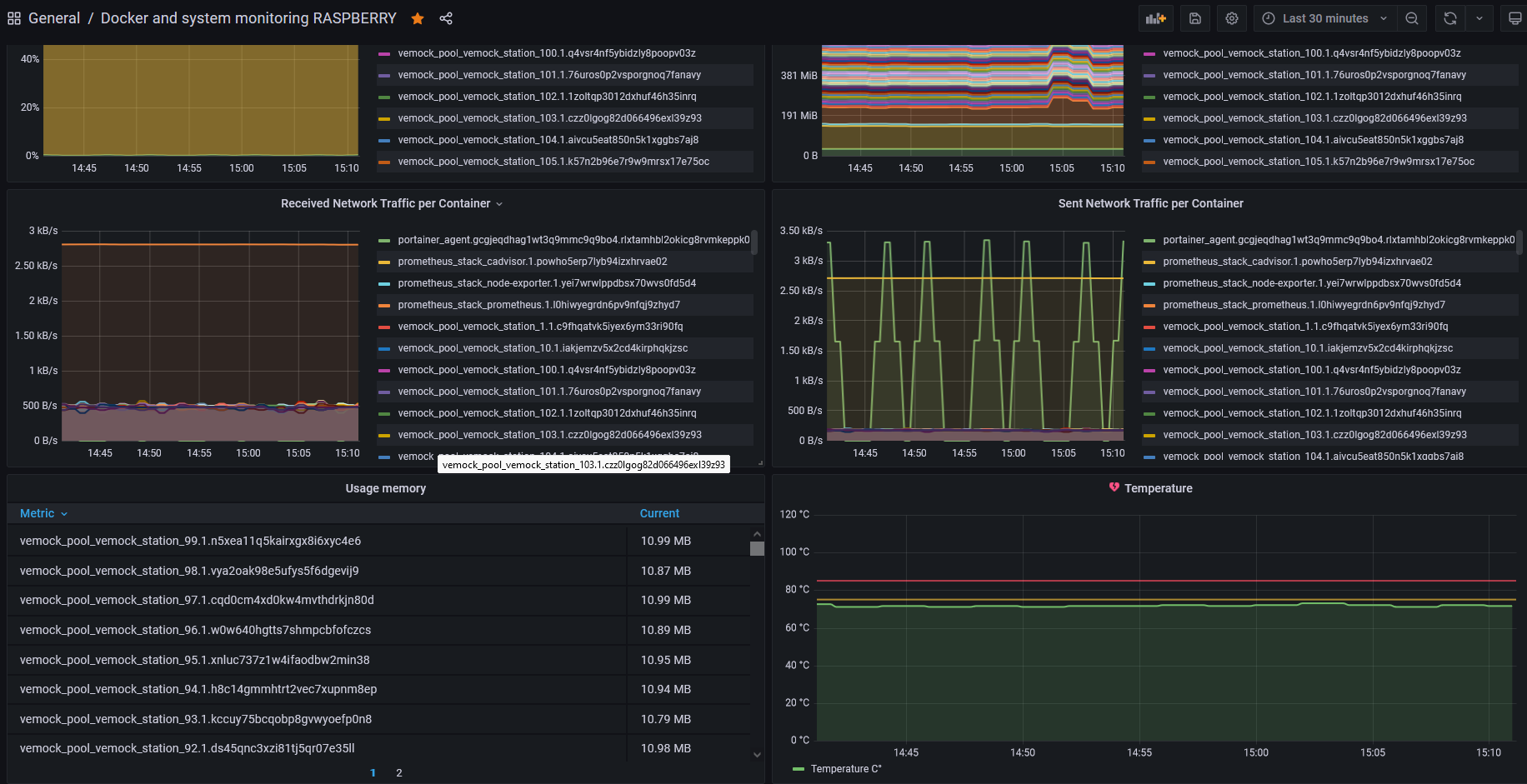
V. Monitoring
Comme nous pouvons le constater, notre architecture serveurs est assez rempli et beaucoup d'applications différentes. Il est donc compliqué de tout surveiller sans aide.
Nous avons donc mis en place une stack docker compose regroupant Grafana, CAdvisor, Node-Exporter et Prometheus. Afin de pouvoir monitorer tout ce qui se passe sur nos serveurs.
1. Grafana & Prometheus
Grafana est un outil open source de monitoring informatique orienté data visualisation. Il est conçu pour générer des tableaux de bord sur la base de métriques et données basées dans le temps.
On peut y connecter différentes bases de données, orientées Time Series (base de données optimisée pour le stockage de données horodatées) pouvant être alimentées grâce à une grande variété d’agents de monitoring. Dans notre cas il s’agira d'une base donnée Prometheus.
2. Node exporter, les métriques systèmes
Prometheus ne sait pas collecter d'informations tout seul. Il lui faut des agents. Le plus simple et le plus complet pour avoir une vision global de la situation d'une machine (CPU, RAM, Load, traffic, etc.) est le bien nommé Prometheus Node Exporter. Il nous permettra d'avoir les métriques globales de la machine.
3. Cadvisor, les métriques Docker
Les containers sont aujourd’hui largement utilisés du développement jusqu’en production. Cependant un docker stats en SSH ne permet pas de gérer correctement son environnement de production.
Cadvisor est une solution rendue open-source par Google qui permet de fournir les ressources utilisées par des containers docker. Cela nous permettra d'avoir des métriques personnalisées pour chaque instance tournant sur nos serveurs
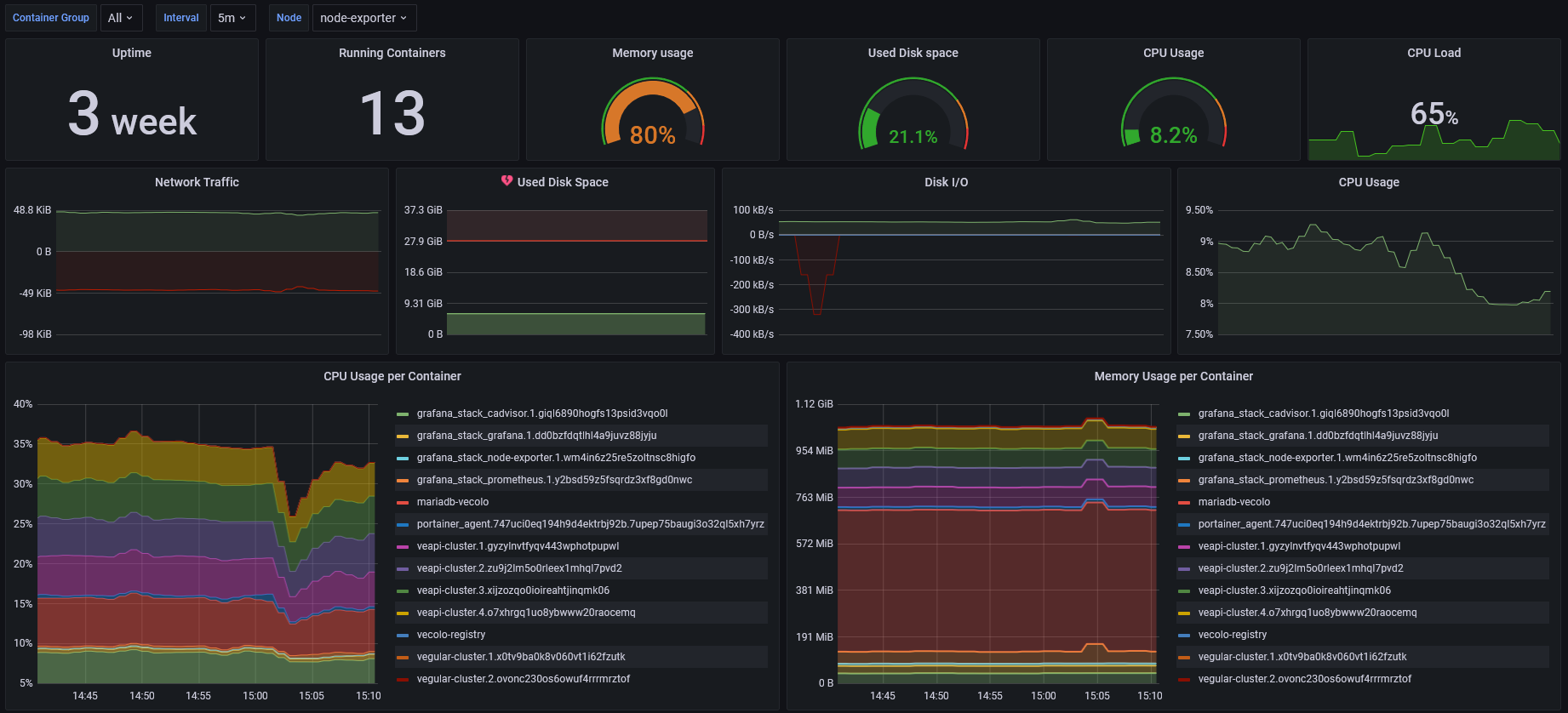
4. Tableaux de bords
Grâce à cette composition, nous possédons 2 tableaux de bord.
· Un pour le serveur principal
· Un pour la Raspberry
Les 2 tableau de bord sont quasi similaires la différence près que nous surveillons également la température de la machine sur la Raspberry car c'est un composant qui chauffe vite.
VI. Bilan du projet
1. Problèmes rencontrés
Docker Swarm et les services
Nous n'avons pas eu de cours de docker cette année et il a donc fallu partir de 0.
Docker Swarm est un concept que nous avons eu énormément de mal à comprendre et nous n'avons pas tout de suite implémenté des services car nous n'y arrivions tout simplement pas.
C'est plutôt vers la fin du projet que nous sommes enfin parvenus à faire ce que nous voulions avec.
Déploiement continue
Nous avons tenté d'abord d'utiliser Jenkins pour le déploiement continu mais nous nous sommes vite retrouvés perdus devant l'immensité de l'outil et le peu d'informations que nous avions à ce sujet.
Ce sont sur les derniers cours de l'année que nous avons pu discuter avec certains de nos professeurs afin de trouver des solutions adéquates pour avoir un développement continu qui tient la route
Mockage de 100 stations
Le mockage des 100 stations était un des plus grands défis de ce projet. Il a fallu beaucoup travailler sur l'optimisation du code pour que cela prenne le moins de ressources possible afin de faire tourner 100 instances simultanées sur une Raspberry.
Le premier montage a été long et fastidieux car il fallait créer 100 stations à Paris à des endroits géographiques cohérents est spécifié dans le docker compose la configuration de chacune.
2. Conclusion
Pour conclure, c'est sans doute la plus grande architecture serveur que nous ayons eu à mettre en place depuis le début de notre scolarité.
Le fait d'intégrer docker dans cela a été une grande nouveauté et nous a permis d'aller beaucoup plus loin que les années précédentes.
Nous sommes très fiers du déploiement continu que nous avons puis mettre en place vers la fin, ainsi que les fameuses stations qui constituent un des gros objectifs du projet.
Enfin, il a été très agréable d'avoir pu monitorer tout ça et surveiller le comportement de nos applications et nos serveurs.
Nous comptons sans doute réutiliser cette architecture pour nos futurs projets
VéAPI
I. Introduction
1. Rappel du sujet
Dans le projet annuel il nous a été demandé de faire une API, dans notre cas cette API n'est en rapport avec l'application java de gestion de projet agile.
Nous avons voulu faire une API uniquement en lien avec le projet Vécolo.
Le cœur de ce projet et d’interagir avec l’application Angular pour lui transmettre des données.
Cette application fait aussi bien d’autre chose, elle a une interface en ligne de commande pour que l’on puisse écrire des scripts que les développeurs puissent lancer. Dans notre cas, nous nous en sommes servis pour faire des « seeds » et remplir la base de données avec des données des tests.
Elle exécute des tâches planifiées pour les factures, et le nettoyage de la base de données.
Le sujet était très libre quant à implémenter cette API en Node JS.
La véritable consigne était celle que l’on se donne. Elle dépend du sujet que l’on avait choisi. Une API c’est le point d’accès à la base de données seul, elle peut à la fois servir pour diverse application frontend mais c’est aussi l’occasion de centralisé son code métier.
II. Focus sur l’application
1. Fonctionnalités
Cette application a pour but principal de permettre à l'application Angular d'interagir avec la base de données et les différents services de Vécolo.
Actuellement, cette application est utilisée par l’application Angular et les Stations autonomes, mais dans notre idée, il est clair qu’elle joue un rôle central sur le projet, elle représente le domaine d'application.
L'application a deux portes d'entrée :
- Via l'API web (Application Angular & Stations autonomes)
- Via la ligne de commande (Seed de la BDD & migrations)
L'application, quant à elle, communique directement avec la base de données.
2. Architecture du code
Nous avons adopté une architecture MVC pour ce projet.
|
 |
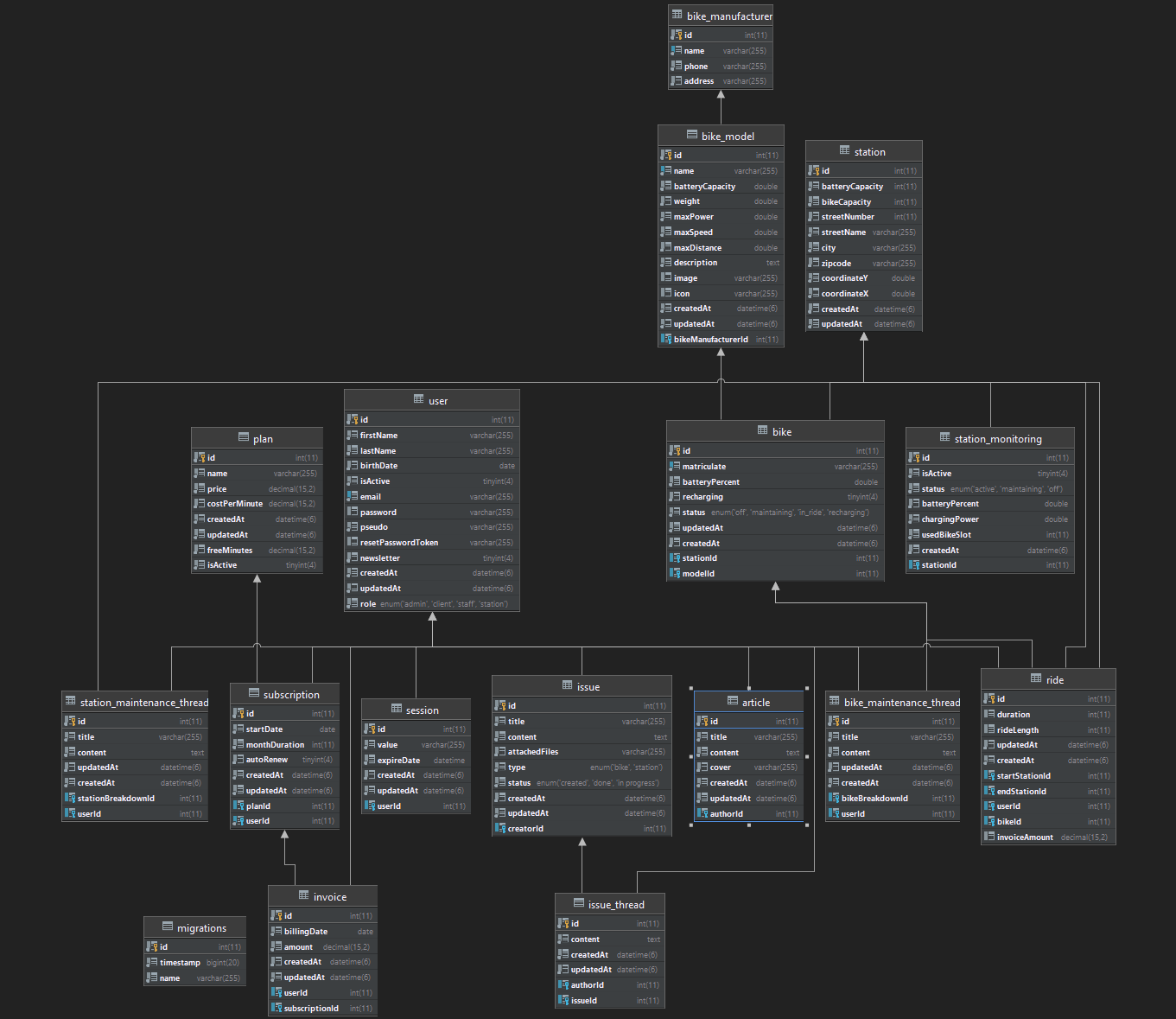
3. Schéma de base de données
Nous avons séparé la base de données de Vécolo de celle de l’outil de gestion de projet.
VéAPI est la seule application en lien direct avec la base de données.
Toutes les autres applications passent par VéAPI quand il s’agit de manipuler des données persistantes.
Dans notre implémentation actuelle, nous utilisons le SGBD MariaDB. La question s’est posée plusieurs fois d’utiliser PostgreSQL mais nous n’avons pas fait le changement.
III. Choix d’implémentations
1. Injection de dépendance
Ce projet fonctionne avec de l'injection de dépendance. Pour ce faire, nous avons utilisé TypeDI qui nous permet de l’implémenter avec des annotations Typescript.
L’injection de dépendance est au cœur des projets Vécolo c’est l’une des nouveautés que l’on essaye d’implémenter désormais. Dans l’univers de javascript, c’est quelque chose d’assez atypique.
Ne sachant pas à quoi nous attendre, nous avons pris le risque de nous aventurer vers l’inconnu et de mettre en place une architecture basée sur ce système, nous ne connaissions pas du tout la librairie contrairement à Spring pour java où nous avions quelques notions, ici la découverte a été totale.
C’est vrai que les systèmes ne fonctionnent pas exactement de la même manière et que cette implémentation est un petit peu plus « root », cela nous a permis d’en apprendre davantage sur le fonctionnement interne de l’injection de dépendance.
2. Typescript
Pour ce projet, nous utilisons Typescript et pas directement javascript, pour l'apport en termes de syntaxe via les types et les annotations. La question ne s’est pas vraiment posée ici, étant donné que si l’on veut utiliser Angular c’est une case quasi obligatoire alors autant aussi utiliser cette technologie en backend aussi.
3. TypeORM
Dans ce projet, nous avons utilisé un ORM, pour s’abstraire des spécificités de la base de données.
Encore une fois ici, on tire avantage des annotations Typescript pour décrire nos entités et nos tables.
On a utilisé les migrations via le système de typeORM et la détection de changement dans les entités.
4. Authentification
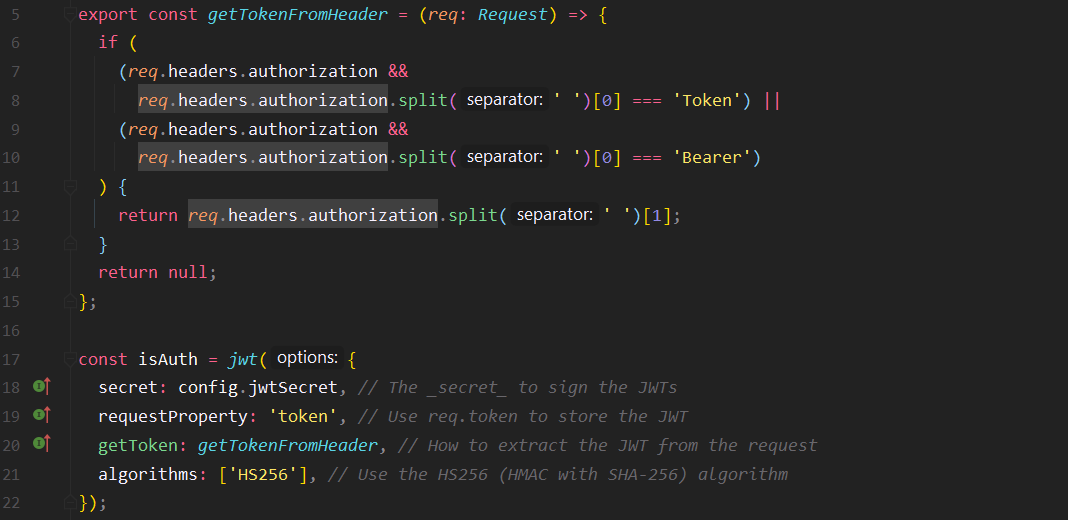
On a choisi JWT (JsonWebToken) pour mettre en place l'authentification ; et ce pour plusieurs raisons.
Premièrement, sa capacité à stocker les sessions sur le client et qui donc nous permet d'avoir des sessions coté client. Ce qui est nécessaire étant donné qu’actuellement l'API est en fait un Cluster de 4 instances régi par un Load Balancer.
Une autre spécificité dans notre utilisation de JWT est le fait que nos stations fassent des requêtes authentifiées à l'API. Pour que cela fonctionne, chaque station a son token qui est à durée de vie illimitée et qui lui permet de s’authentifier sur les routes pour le monitoring. Toutes les autres routes leur sont interdites.
Pour répondre à la problématique d'authentification d'utilisateur, on utilise les librairies : jsonwebtokenet et express-jwt.
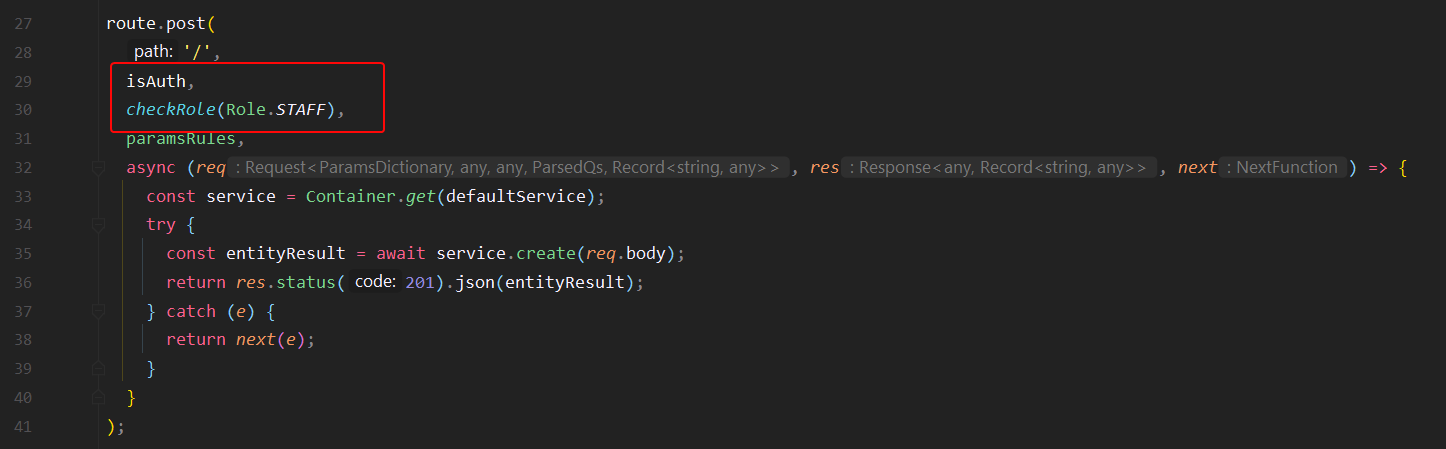
5. Problématique des rôles
Pour répondre à la problématique des rôles et de l’accès au point d’entrée de l’API, nous avons utilisé des middlewares sur les routes pour filtrer les requêtes.
6. Informations privées
Pour ce projet, nous avons utilisé dotenv et des fichiers d’environnement .env dans lesquels nous stockons les informations qui ne doivent pas être partagées sur le dépôt public.
Cependant, nous avons un fichier .env.example pour indiquer à l’utilisateur comment remplir le fichier .env.
Les informations de configuration sont stockées dans un objet « config » qui nous permet de charger les données du fichier au démarrage dans une variable pour pouvoir derrière utiliser ces données partout dans l’application.
7. Lintage
Pour s’assurer une propreté optimale dans notre code, une configuration EsLint avec prettier a été installé pour ce projet pour formater le code de manière uniformisé.
Étant donné que le projet est en Typescript, nous utilisons aussi des extensions EsLint et prettier pour cet usage.
8. Validation des requêtes http
Pour gérer la vérification des données envoyées à l’API, on utilise Celebrate et Joi.
Celebrate encapsule Joi pour en faire un middleware.
On décrit un schéma de ce qui est attendu comme contenu dans la requête entrante avec ces outils et on laisse Celebrate effectuer le travail. C’est lui qui va bloquer les requêtes non conformes et renvoyer un message d’erreur.
9. Upload de fichier
Dans le projet actuellement, nous avons une fonctionnalité d’upload de fichier pour les images des modèles de vélos.
Étant donné qu’il y a 4 instances de l’API et que nous sommes sous docker, nous avons dû monter un volume partagé entre toutes les instances.
10. Logging
Pour les logs, nous avons aussi besoin d’un volume docker partagé entre les instances.
Nous utilisons la librairie winstonjs, qui nous permet de gérer jusqu’à 6 niveaux d’erreurs.
Les logs sont enregistrés dans deux fichiers. Un premier pour les logs de type erreur et un autre pour ceux du niveau informatif.
11. CRON
Parmi les éléments qui sont chargés par l’application, il y a des « schedulers », dans notre cas deux schedulers sont présents :
· Un est présent pour nettoyer de la base de données les enregistrements de monitorings générés des stations par Vemock.
· Un autre est présent au début de chaque mois pour créer de nouvelle facture pour les abonnées dont l’abonnement continue.
12. Seeds
Pour remplir la base de données, nous avons mis en place des scripts de « seeds ».
Ces scripts vont faire appel à des « Factory object » pour insérer des éléments dans la base de données.
De fausses données sont générées à partir de faker js, l’interface CLI (qui permet de nous demander la quantité de donnée désirée a été faite avec inquirer.
13. Mailing
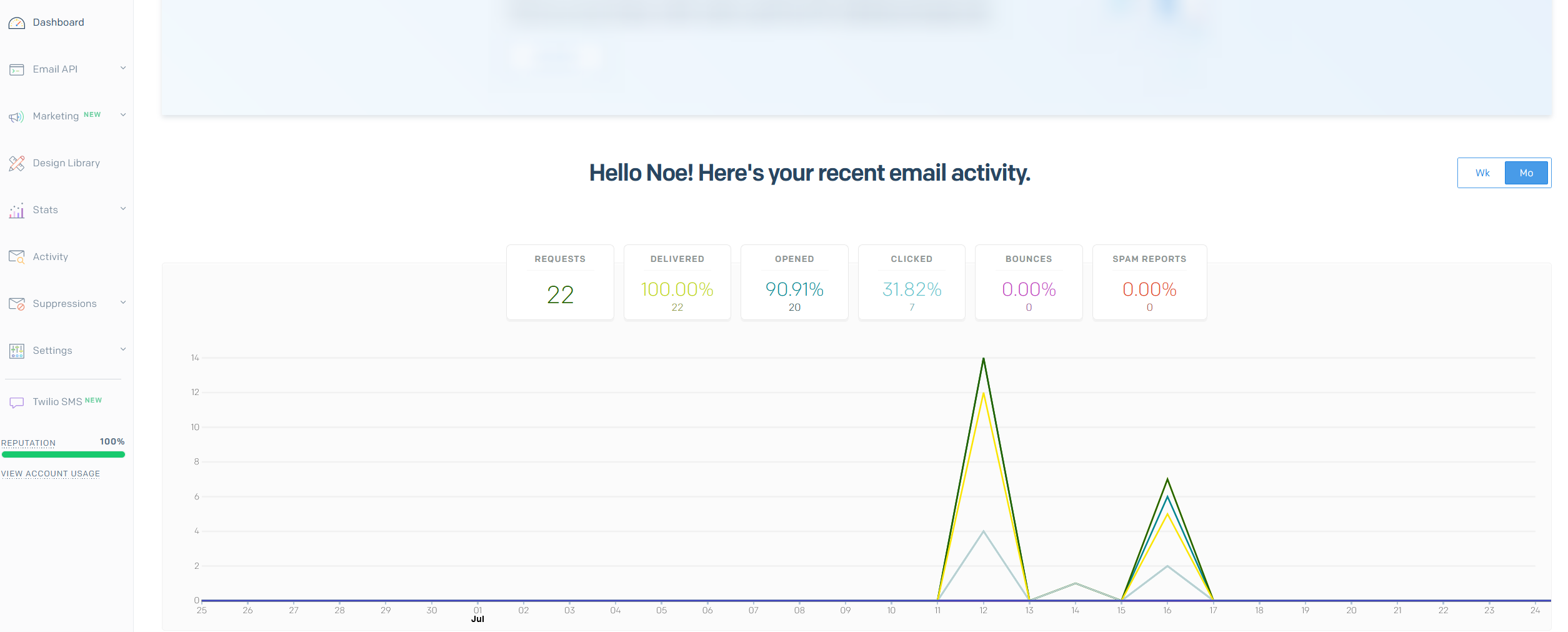
Lorsque que nous devons envoyer des mails (newsletter, réinitialisation de mot de passe) depuis l’application Angular, c’est à l’API de s’en occuper, de traiter le contenu à envoyer, puis d’utiliser un service externe Sendgrid pour envoyer le mail.
Sendgrid
Sendgrid est un service d'envoi de mails, permettant de construire des modèles dynamiques pour ces derniers. C’est lui qui va se charger d’utiliser notre nom de domaine vécolo pour gérer les envoie de mails. Cela nous permet d’avoir une interface adaptée à ce besoin et d’alléger notre application API.
IV. Bilan du projet
1. Appreciation générale et organisation du projet
Ce projet a été marqué par trois périodes :
· Dans la première ; au moment où le projet n’est pas encore lancé et que l’on était à la genèse de cette API.
On a eu un travail de recherche sur l’architecture de cette application. C’est dans cette étape qu’on a pu retrouver des tentatives avec swagger, que l’on a changé l’interface de ligne de commande, que l’on a créé nos premières entités, nos premiers service auto injectés à partir de TypeDI.
· Dans un deuxième temps, au lancement de l’application Angular, nous avons laissé Clément s’occuper de cette application, c’était son souhait. Clément n’est pas allé jusqu’au bout du projet… Que ce soit un manque d’investissement ou de communication avec les autres membres et un manque d’intérêt pour le sujet ; le fait est que les choses n’ont pas été faites comme elles auraient dû et qu’il a fallu prendre un peu de temps pour pérenniser le travail déjà accompli.
· Dans un dernier temps ; l’application Angular avançant ; nous avions besoin de certains fonctionnalités plus spécifiques sur l’API. Il a fallu repenser certaines choses car ces points d’entrés fonctionnent différemment de la manière dont ils ont été pensés à la base.
Nous avions aussi besoin de compléter l’API avec des requêtes auxquels nous n’avions pas pensés à l’origine.
2. Problèmes rencontrés
Au fur et à mesure du temps passé sur ce projet, nous avons décelé un souci dans l’architecture de l’application. Dans la structure que nous avons pensé au début, nous définition les routes dans le router et c'est lui qui gérait les entrées et sorties de l'application. Mais au fur et à mesure de l'avancement, et le projet grandissant, notamment sur la gestion des erreurs, nous nous sommes rendu compte que certaines choses n'étaient pas à leur place. Cela s’est vu notamment sur la question des erreurs et du code de retour http qui a parfois finit dans les services, et globalement il aurait été bien de découper le code pour le rendre plus claire. Cela nous aurait aussi aider pour nous y retrouver plus facilement sur les routes.
Un autre problème que nous avons rencontré est un problème avec les migrations typeORM. Les migrations ont besoin d'être exécutées depuis un environnement Typescript par le script de typeORM et sur Windows, nous avons eu des problèmes pour générer les migrations. Heureusement, c'est un problème connu de typeORM, malheureusement sans solution magique. Cependant avec de la recherche, nous avons réussi à trouver la ligne de commande qui nous permet de bien générer nos migrations sur Windows.
Avec typeORM, dans certain cas pour des requêtes un petit peu plus complexe, notamment les "groupe by", nous avons été contraints à utiliser le querybuilder et ça n'a pas forcément été « agréable » car on perdait le côté « utile » de l’ORM.
Avec le temps, nous nous sommes faits à l'utilisation et à la syntaxe, mais le dernier problème que l'on a rencontré est un problème d'organisation. En raison de l'ordre des rendus est des objectifs de chacun il était demandé de finir l'API avant d'avoir fini l'application frontend et donc de s'avancer sur les futurs besoins de l'application, ce qui a été un peu difficile et souvent raté.
3. Conclusion
Pour conclure nous sommes très fiers de l’architecture de cette application c’est un pari risqué car même si l’architecture n’a pas été conçu par nos soins de A à Z, elle a quand même beaucoup été customisé pour répondre à notre besoin, donc nous nous somme approprié le code par la même occasion. C’était encore plus risqué étant donné que l’écosystème javascript est vaste, changeant, et que les librairies n’ont pas toujours été pensées pour fonctionner ensemble. De plus, nous débutons dans l’univers du NodeJS.
Végular
I. Introduction
1. Rappel du sujet
Pour ce projet, il a été demandé de réaliser un client web Angular à destination des utilisateurs et un autre à destination des administrateurs. Après échange avec le parti prenant, il nous a été accordé de ne faire qu’une seule application, qui fera correctement la séparation entre la partie administration et la partie client.
Cette application est au cœur de Vécolo. C’est la partie visible de l’iceberg. Elle doit permettre au client de se connecter, d’interagir avec les vélos et de suivre son compte, ses factures ainsi que son abonnement.
C’est aussi cette application qui va permettre aux administrateurs et aux membres du staff de :
· Gérer les vélos
· Gérer les abonnements
· Gérer les trajets
· Gérer les stations
· Consulter les statistiques
2. Application choisie
Nous avons choisi de ne réaliser qu’une seule application car voulant tirer parti d’Angular, des Guard et des services, il nous était possible de ne faire qu’une seule application plus importante et certes plus dangereuse mais, qui nous permettra d’éviter de la duplication de code et d’alléger la charge serveur.
II. Focus sur l’application
1. Page d’accueil de Vécolo
La page d'accueil est très importante car c'est sur ça que vont tomber les utilisateurs la première fois qu'ils accèdent au site. Elle doit être donc bien travaillée pour capter directement l'attention de l'utilisateur.
La page d’accueil est découpée en 4 parties :
· Présentation
· Actualité
· Tarif
· Contact
Ces quatre parties ont pour but d’être chaleureuses et accueillantes pour un utilisateur non inscrit, étant donné que c’est l’une des seules choses qu’il pourra voir avec la carte.
Les quatre sections sont disponibles à partir d’un scroll horizontal, ou d’un petit menu en bas de l’écran. Chaque section prend toute la largeur de l’écran.
Ces sections ont pour but de présenter l'application au client de la manière la plus simple possible pour lui donner envie de s'inscrire.
Présentation
La section présentation de Vécolo donne à l'utilisateur toutes les informations sur qui nous sommes et quel est notre service. C'est la page vitrine.

Actualités
La section actualité permet de montrer les articles en vogue du site, pour donner envie à l'utilisateur de s'investir dans la communauté de Vécolo.
Tarif
La section tarif présente les trois formules majeures de Vécolo, qui sont au nombre incroyable de 3.
Contact
La section contact permet à l’utilisateur d’envoyer un message au staff de Vécolo (sur l’adresse contact@vecolo.fr)
2. Carte interactive
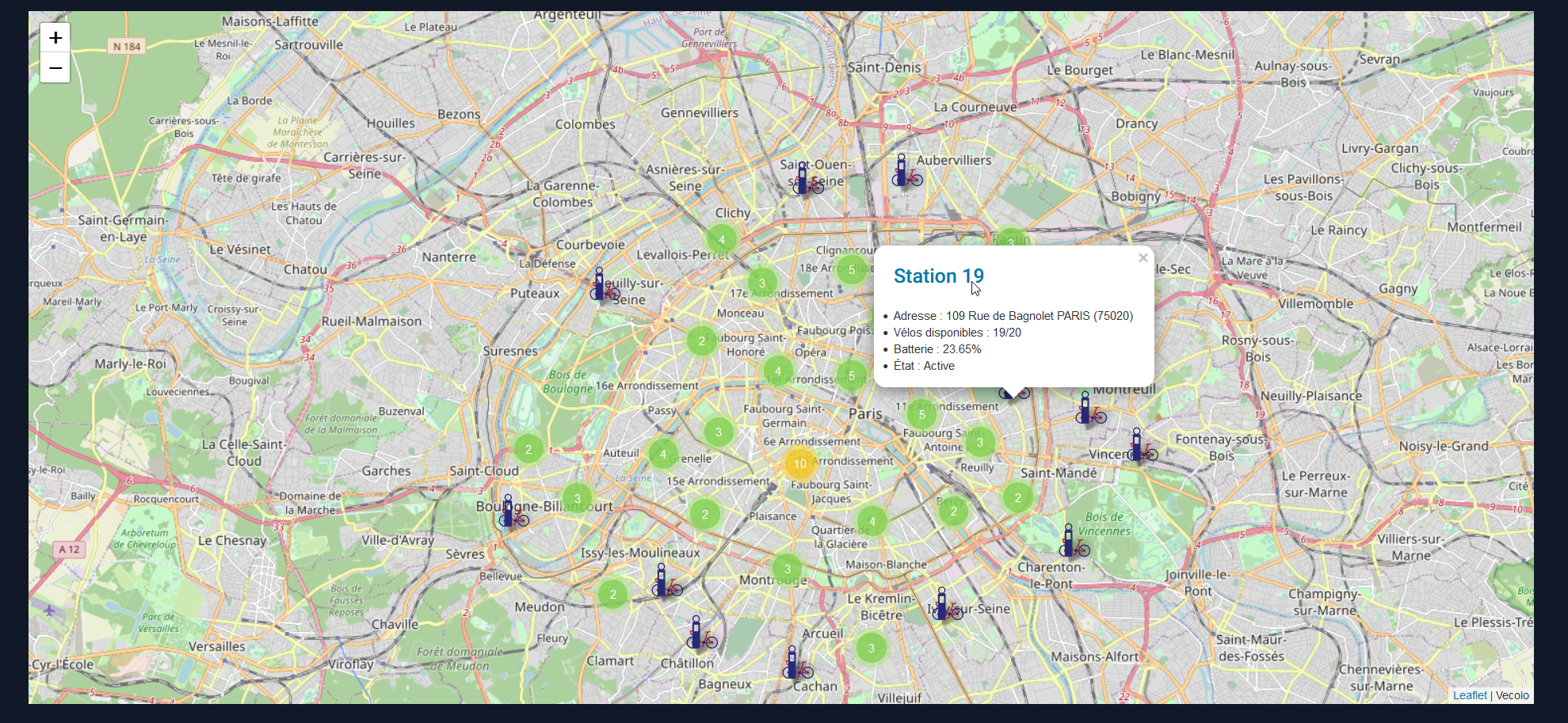
La carte interactive est sans doute la fonctionnalité majeure du site.
Elle permet publiquement de consulter sur une carte les stations Vécolo en temps réel.
Lorsque nous cliquons sur une station il est possible de consulter son état à travers une petite pop-up qui présente les informations principales. On peut à partir de là bien entendu aller consulter directement l'interface de consultation de la station en question.
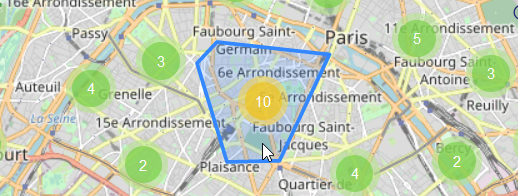
Cluster
Pour ne pas surcharger la carte à cause du grand nombre de stations présentes en région parisienne.
Lorsque le zoom est assez éloigné et que beaucoup de stations sont à proximité les unes des autres, celles-ci sont affichées sous la forme d'un cluster pour une meilleure lisibilité.
OpenStreetMap
Les tuiles de la carte sont entièrement récupérées depuis un service open source et 0% Google, le bien nommé OpenStreetMap.
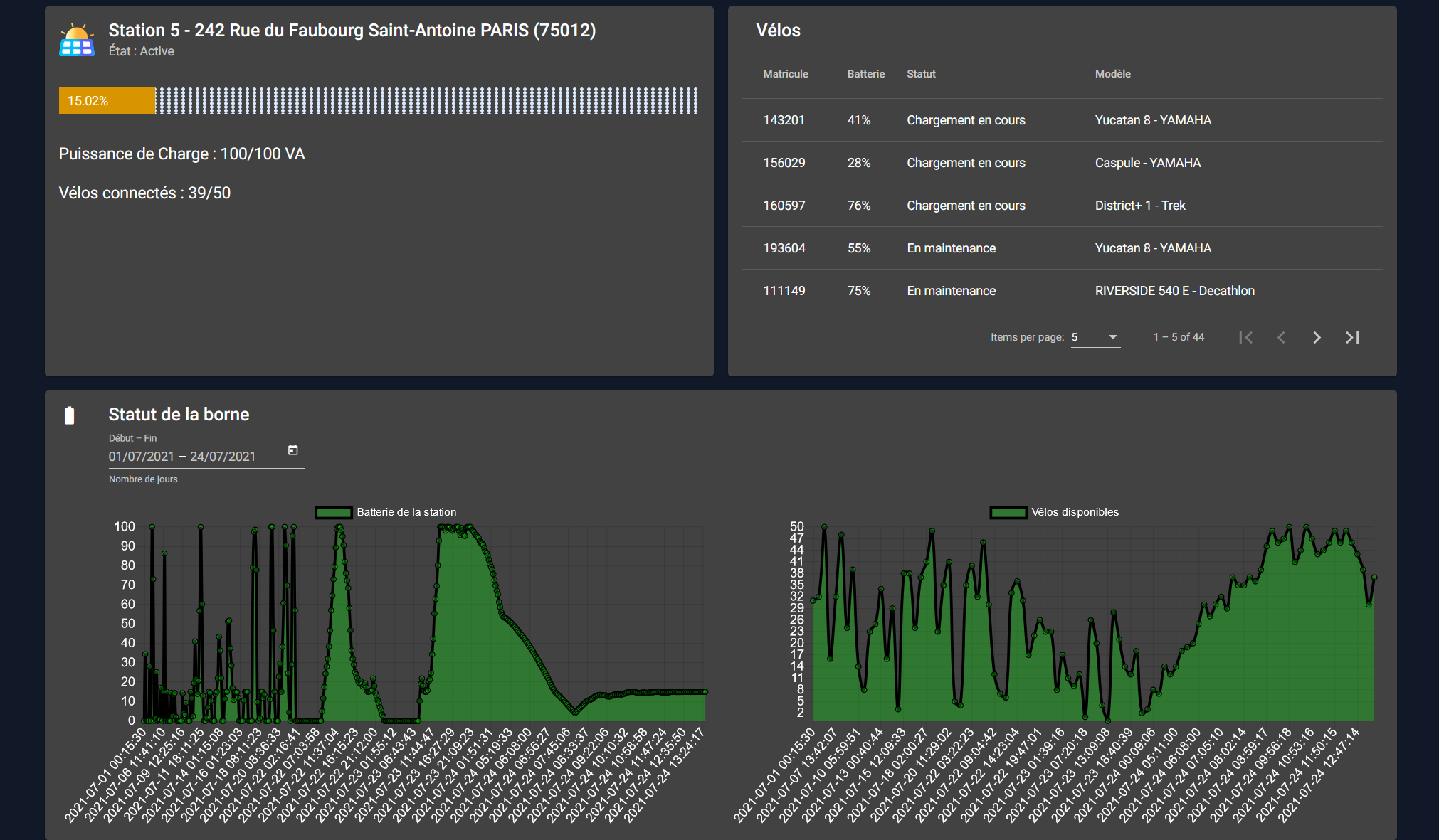
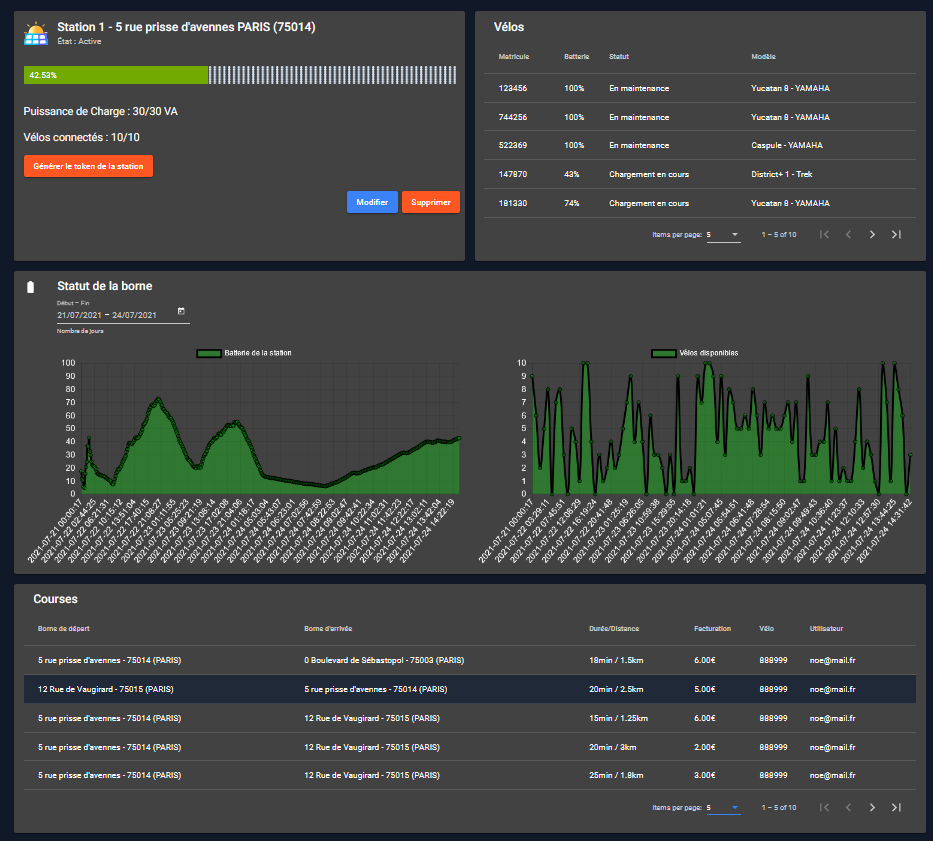
3. Consultation d’une borne
Quand nous consultons une borne, la première information qui apparait pour l’utilisateur est son niveau de batterie et les vélos qui sont en charge à cette station.
Ensuite vient une liste plus détaillée des vélos qui lui sont attribués.
Pour finir, il y a deux graphiques qui montrent l’évolution de la batterie et les nombre de vélos disponibles sur une durée configurable.
4. Inscription
On peut s’inscrire sur le site via la page d’inscription dans laquelle il nous faudra rentrer quelques informations personnelles.
Il faut également valider un captcha, un compte client est ensuite créé.
5. Connexion
Pour se connecter à l’application, il faut être inscrit. La connexion se fait avec un email et un mot de passe et en remplissant le captcha. Peu importe notre rôle, le point d’entrée dans l’application est le même que l’on soit staff, administrateur ou client.
Si l’on a oublié son mot de passe, on peut cliquer sur le lien « j’ai oublié mon mot de passe », entrer son email. Un lien de réinitialisation nous est envoyé par email si l’on est client.
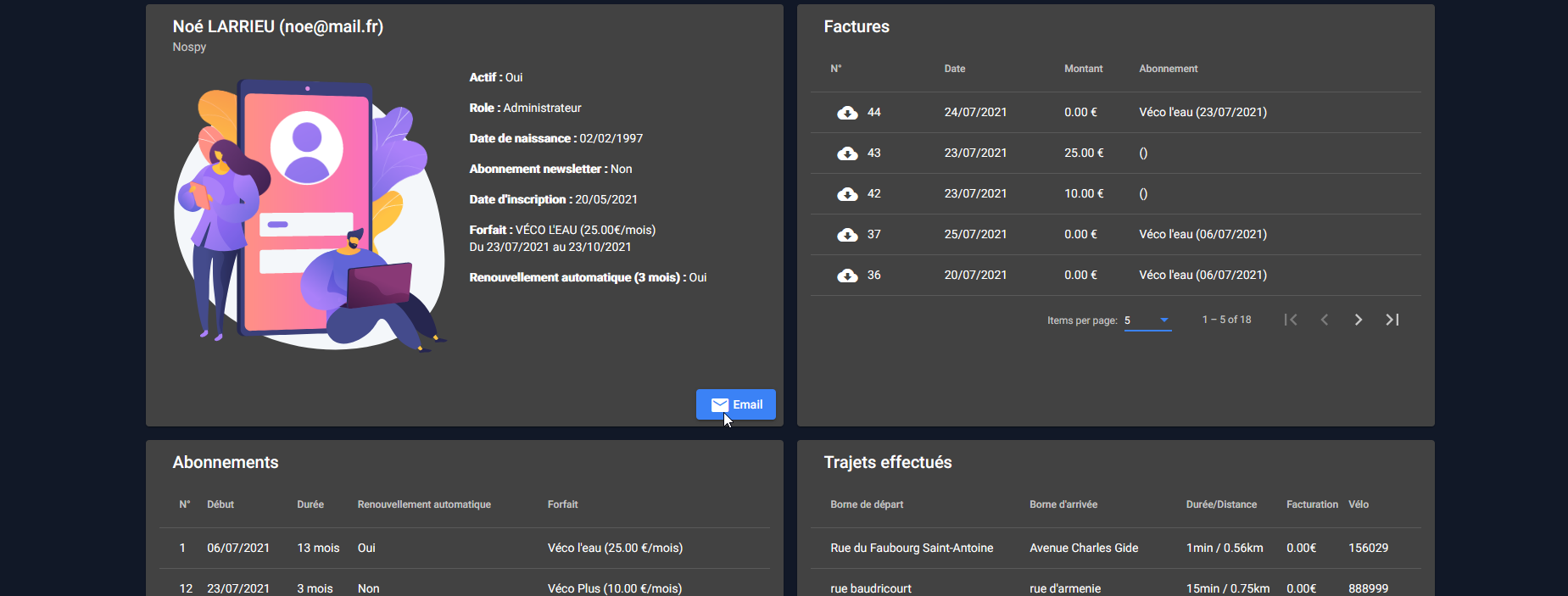
6. Profil utilisateur
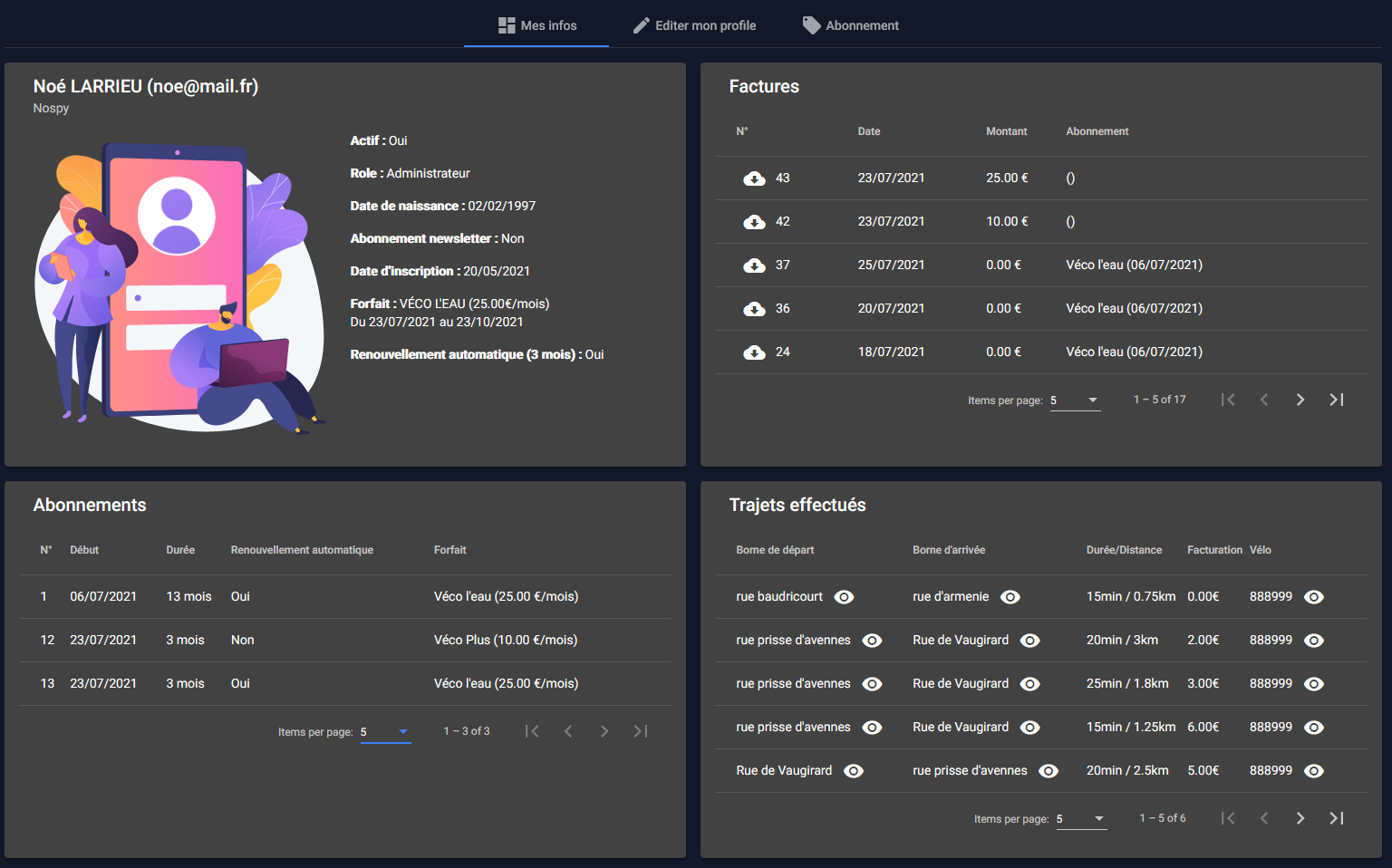
Une fois connecté, on accède à son profil.
Cette vue est divisée en trois sections ; la consultation des informations de l’utilisateur, l’edition du profil ainsi que la gestion de son abonnement.
Consultation du profil
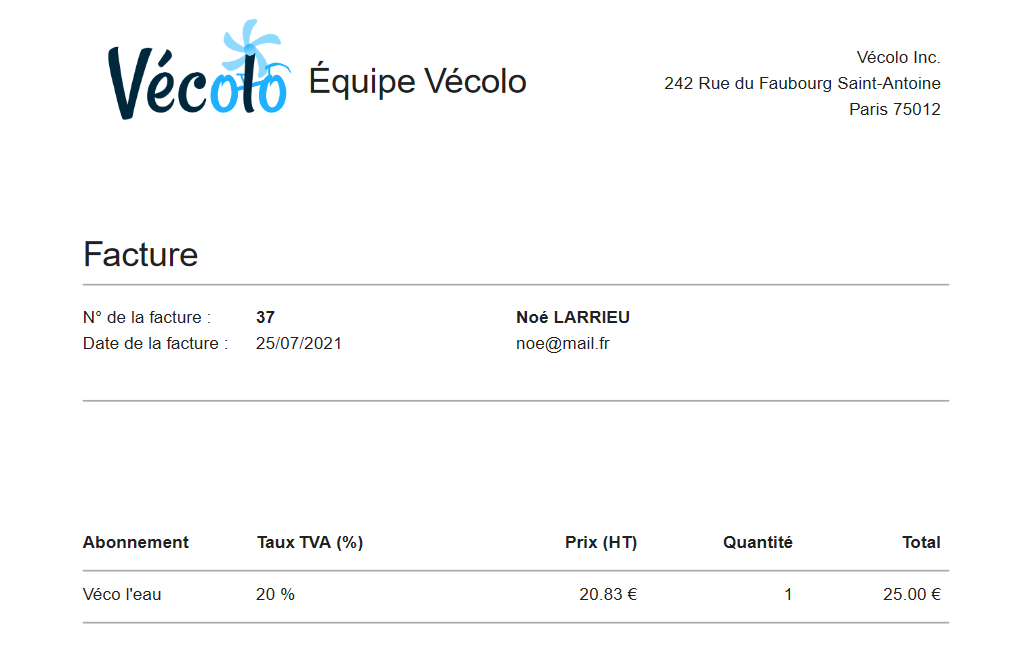
Cette page permet de consulter directement les informations de l’utilisateur, l'historique de ses factures ainsi que des abonnements pris et les trajets effectués.
Il est possible d'exporter ses factures au format PDF.
Modifier ses informations
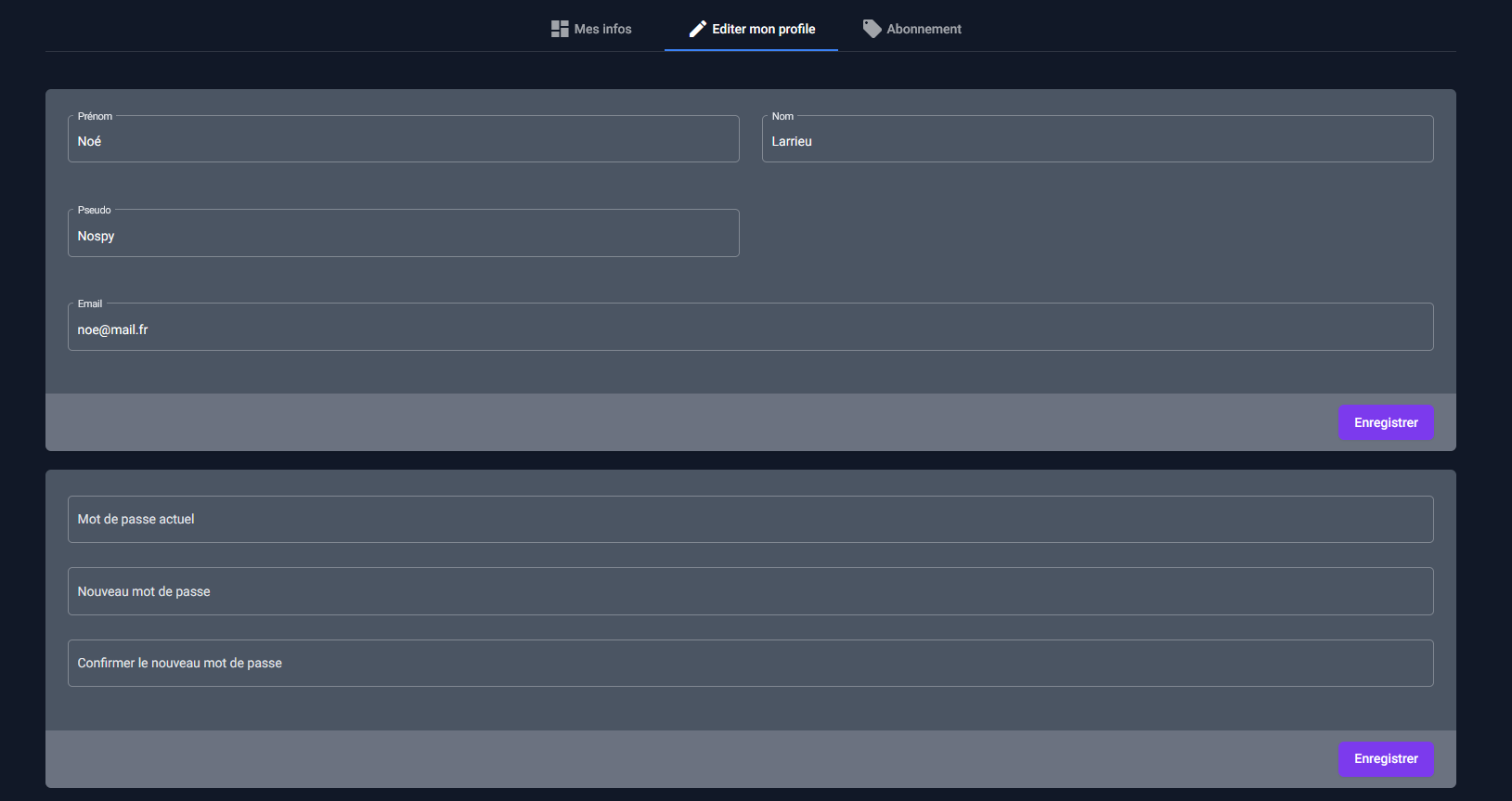
Cette page ressemble beaucoup au formulaire d'inscription et permet de modifier ses informations personnelles ainsi que son mot de passe.
Abonnement
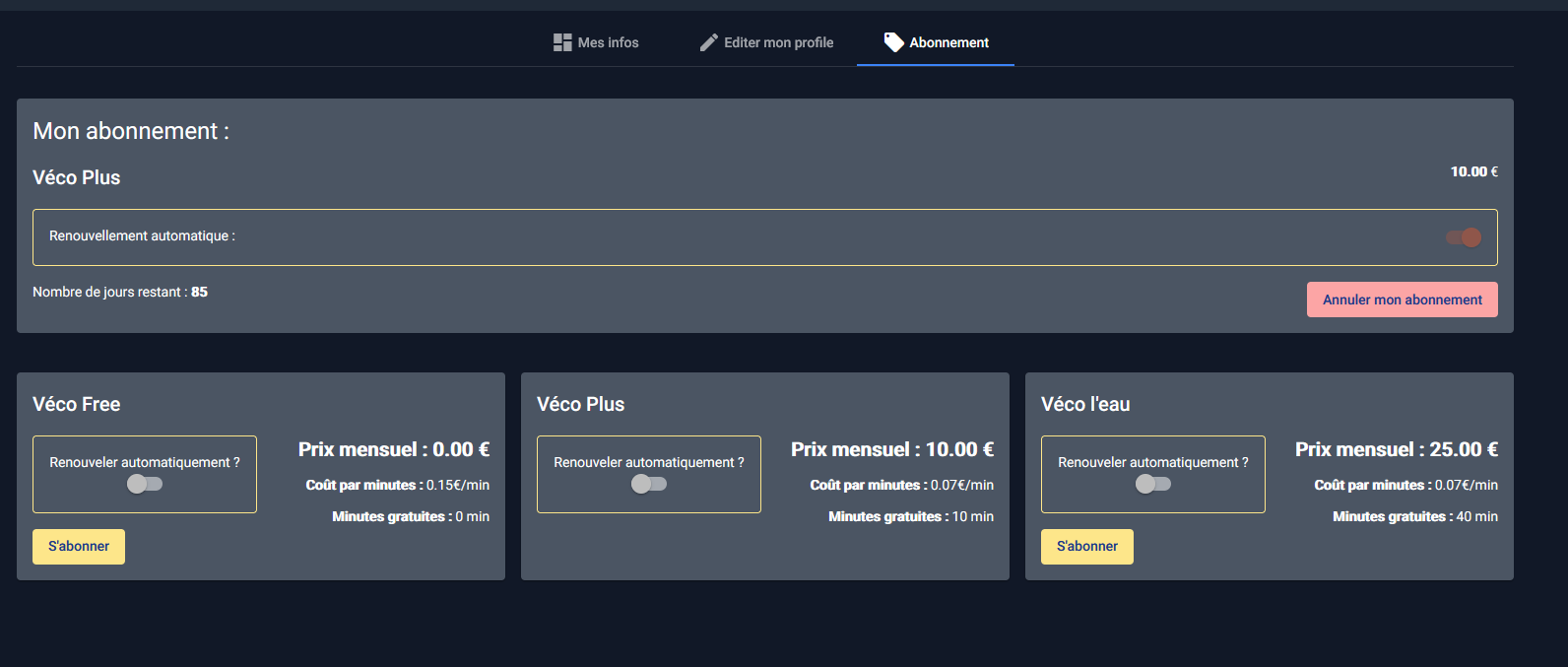
Cette page permet de consulter son abonnement actif. On peut également depuis celle-ci annuler, changer de forfait, ou encore modifier le renouvellement automatique.
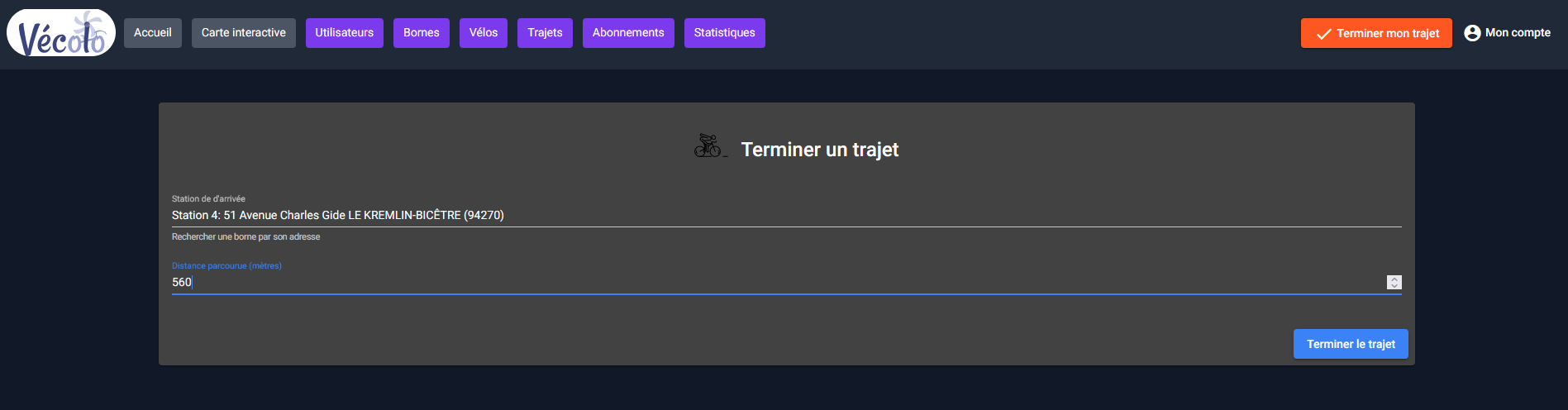
7. Effectuer un trajet
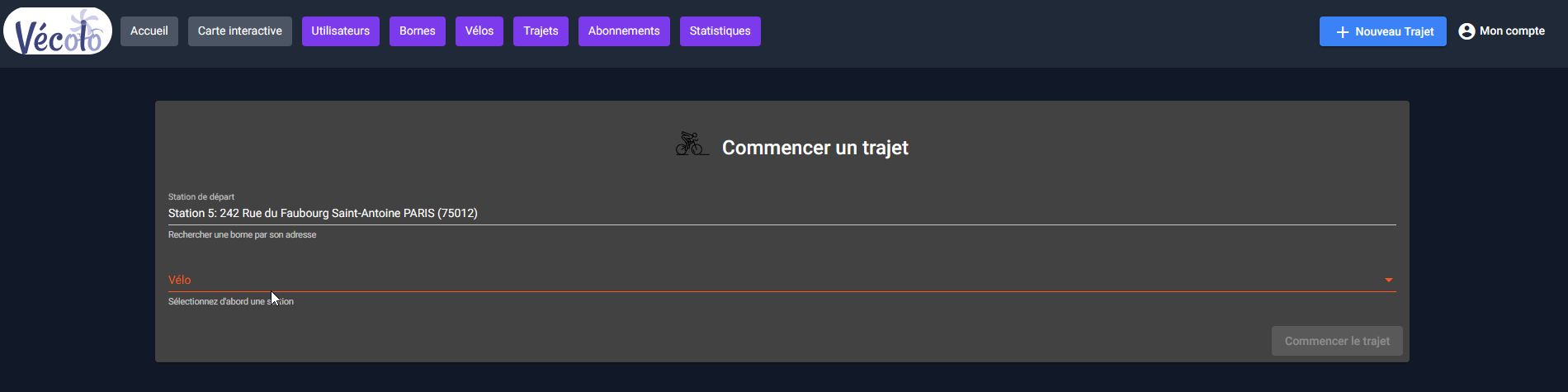
Une fois connecté en tant que client ou membre du staff, il est possible d’effectuer un trajet, à condition d’avoir un abonnement actif.
Pour ce faire, il suffit de cliquer sur le bouton « nouveau trajet » présent sur le menu principal et de saisir la station de départ ainsi que le matricule du vélo.
On pourra ensuite terminer un trajet, cliquant sur le bouton terminer mon trajet, présent au même endroit sur le menu principal. Il faudra ensuite renseigner la station d'arrivée ainsi que la distance parcourue (la saisie de la distance parcourue et temporaire, car dans la version définitive, c'est le vélo qui communiquera cette information).
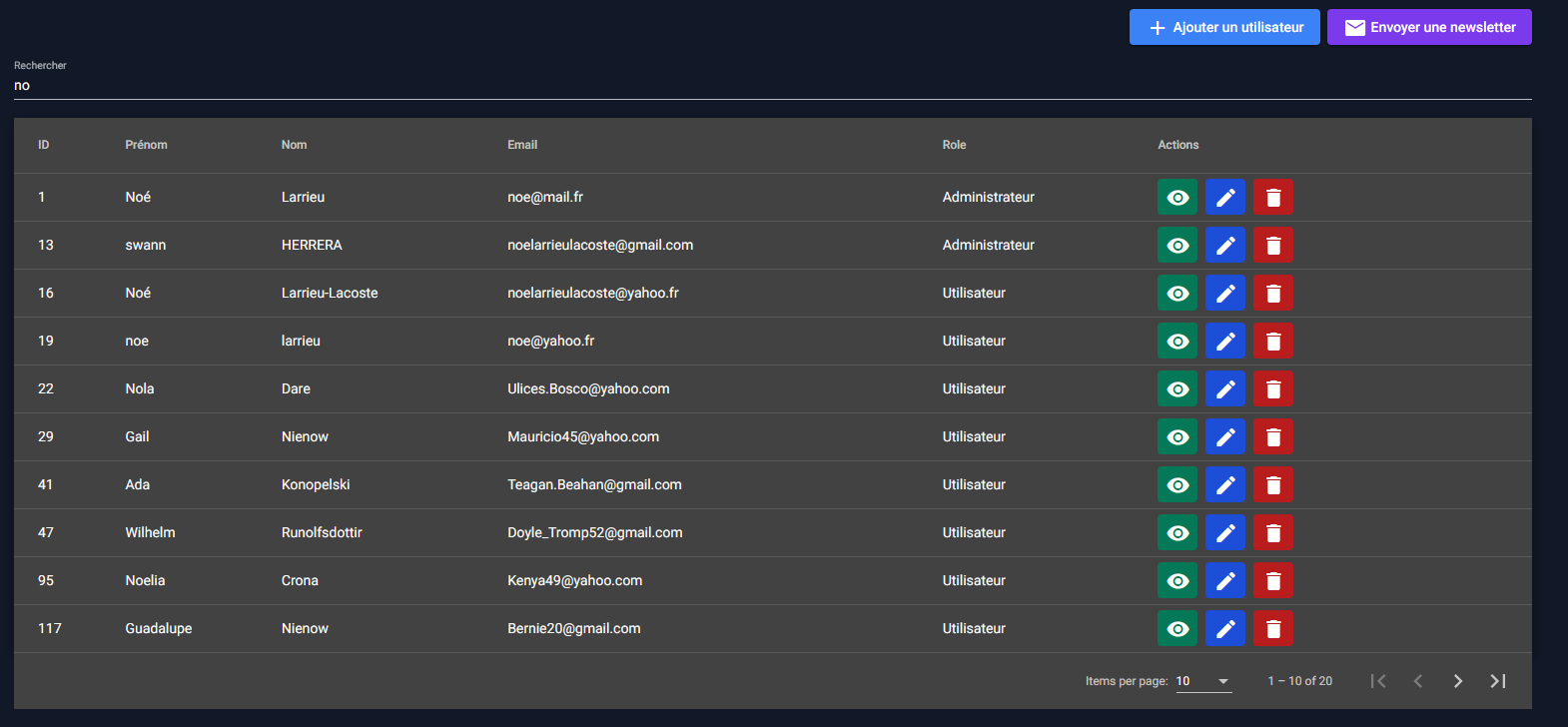
8. Gestion des Utilisateurs (Staff)
Liste des utilisateurs
Les membres du staff peuvent consulter la liste de tous les utilisateurs inscrits sur le site.
Comme il peut y avoir beaucoup d'utilisateurs, le tableau de résultat n'est pas chargé en une fois, mais il est fractionné grâce à la pagination.
Il est possible d'effectuer une recherche sur ce tableau en tapant des mots-clés dans la barre de recherche. On peut rechercher sur le nom, le prénom, l'adresse mail ou le rôle.
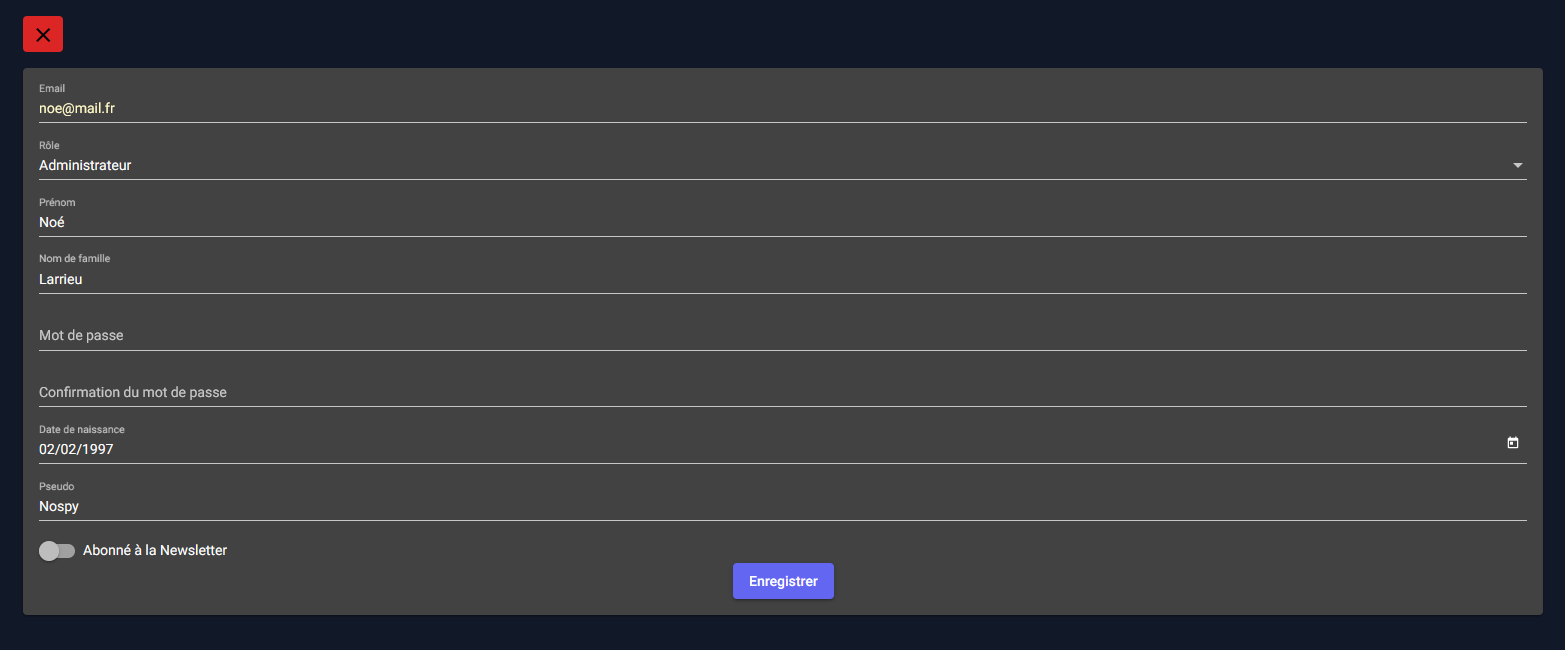
Création et modification d’un utilisateur
L'interface de création et modification d'un utilisateur est la même, à la différence que lors de la modification, les champs seront préremplis.
On peut ainsi ajouter directement des utilisateurs au sein de Vécolo depuis l'interface du staff.
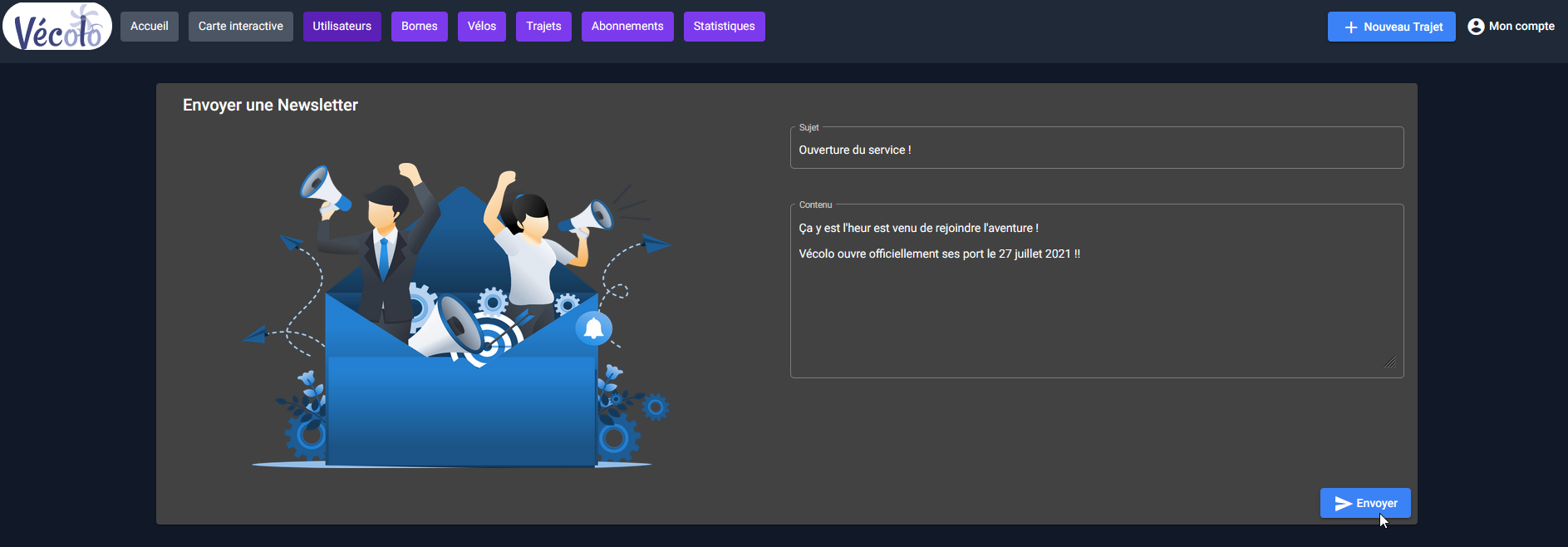
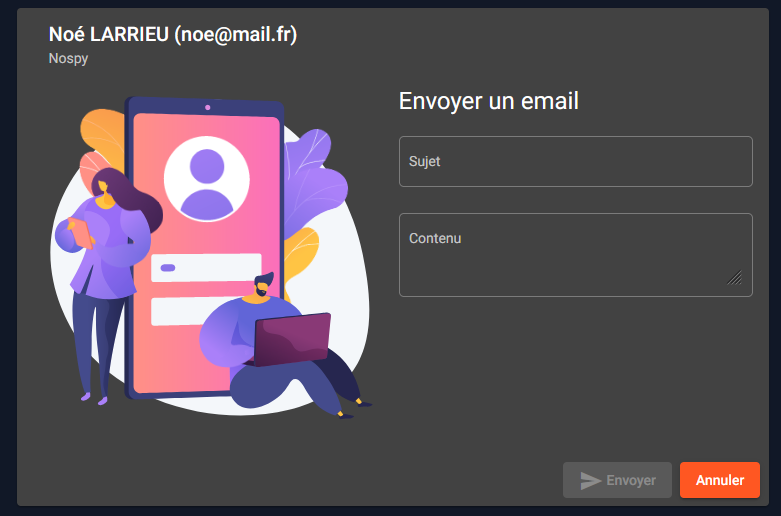
Envoi de mail et newsletter
Un bouton pour envoyer une newsletter est présent sur la page qui liste les utilisateurs.
On peut y saisir le sujet du mail ainsi que son contenu.
Ce mail sera envoyé uniquement aux utilisateurs ayant activé les newsletters.
Il est possible également d'envoyer un mail un utilisateur unique depuis la page de consultation de ce dernier.
Cette page est la même que lorsqu'on consulte son profil à la différence de ce fameux bouton pour envoyer un mail.
 |
 9 9 |
9. Stations (Staff)
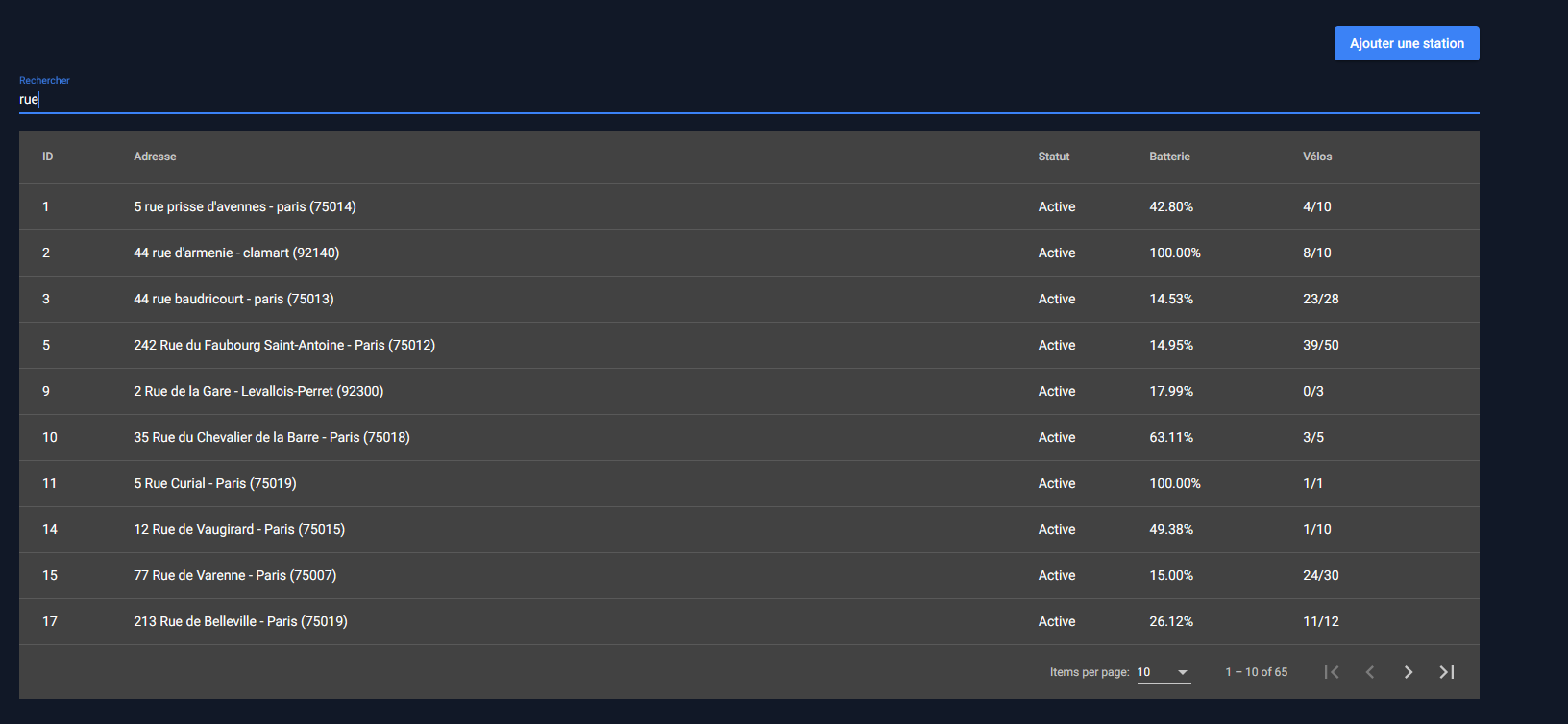
Liste des stations
Les membres du staff peuvent consulter la liste de toutes les stations enregistrées sur Vécolo.
Il est possible de les rechercher par adresse, par batterie ou par statut. Comme nous avons beaucoup de stations, les données sont aussi paginées sur ce tableau.
Ajout d’une station
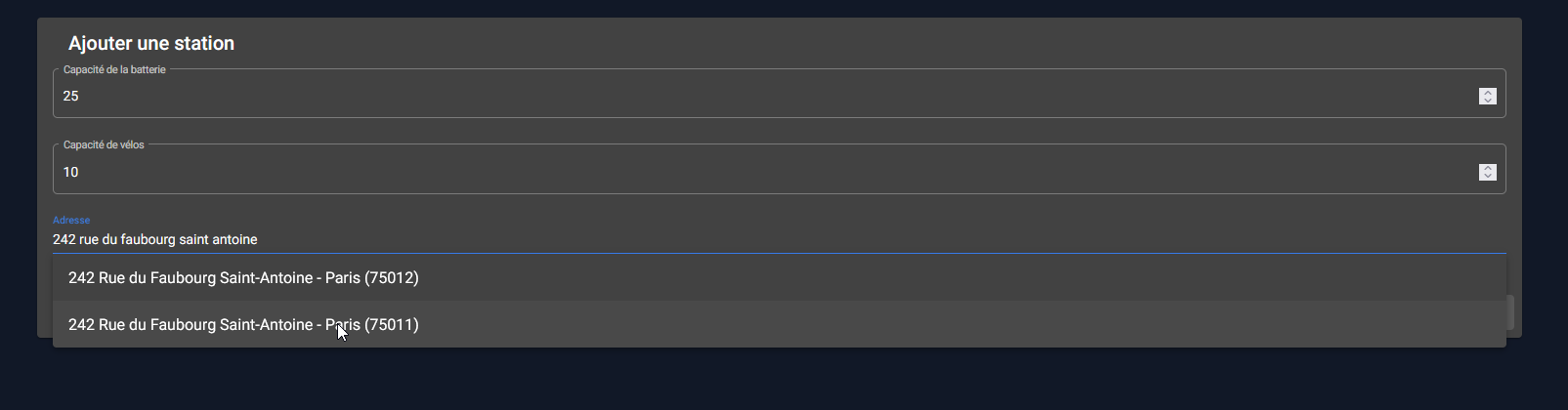
On peut très rapidement ajouter une station. Pour cela, il suffit de remplir le formulaire qui va demander la capacité de la batterie, le nombre d'emplacements vélos disponibles ainsi que l'adresse de la station.
Le champ de recherche d'adresse va utiliser un normaliseur codé grâce à OpenStreetMap qui va nous permettre de récupérer les coordonnées XY en fonction d'une adresse.
Consultation et modification d’une station
La consultation d'une station est sensiblement la même que celle côté clients, à la différence près qu'il sera possible de modifier ou supprimer la station, mais également de voir les trajets effectués en provenance ou à destination de celle-ci.
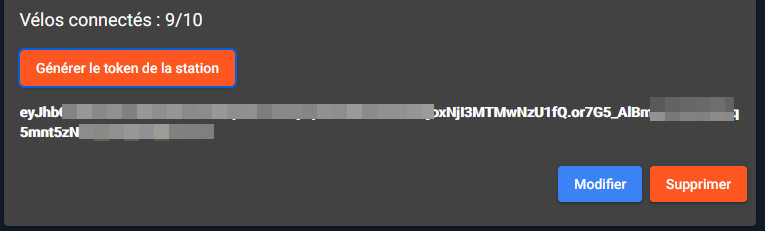
Génération du token
Pour que la station puisse être raccordée et avoir des métriques, il faut qu'elle soit authentifiée à l'aide d'un token qui est général depuis la page de consultation lorsqu'on est administrateur.
10. Vélos (Staff)
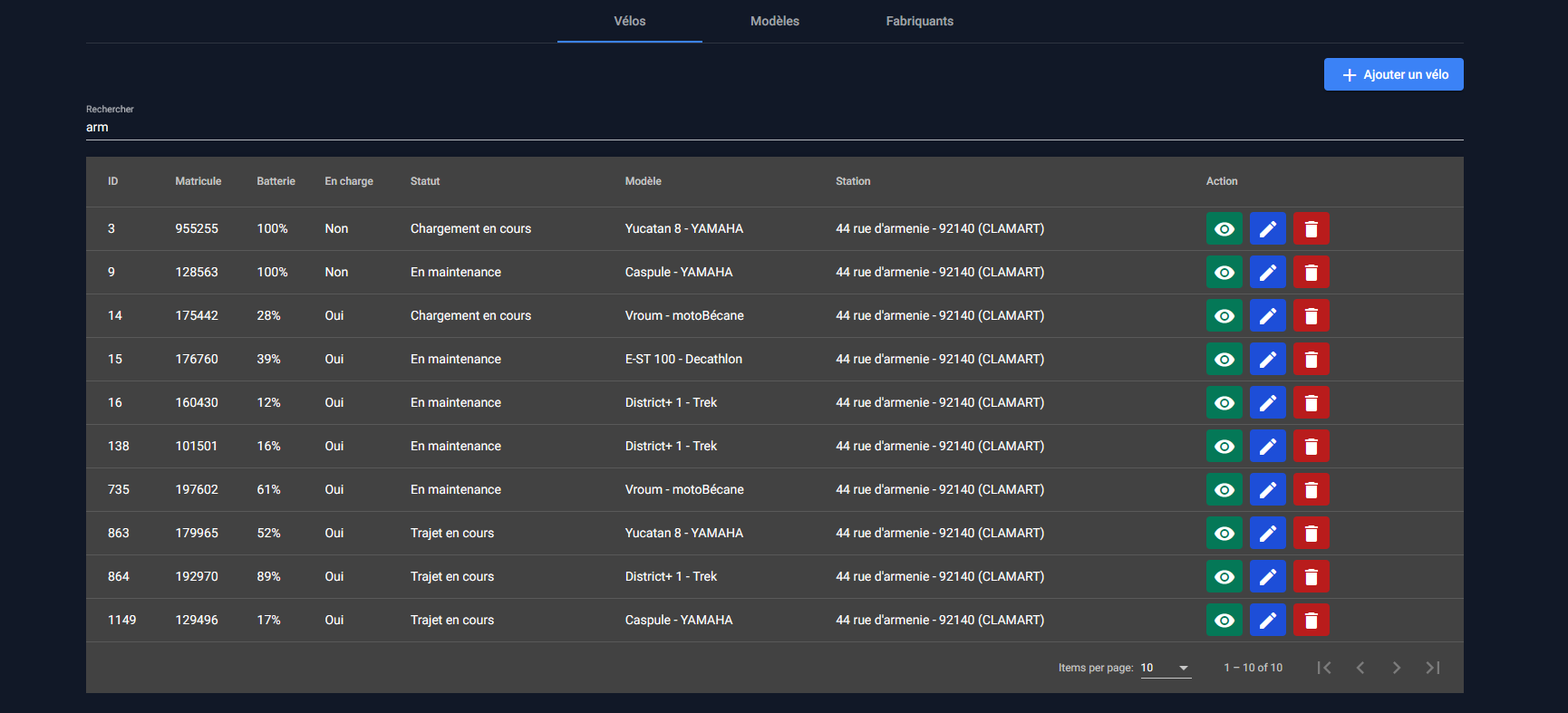
Liste des vélos
Il est possible pour les membres du staff de consulter tous les vélos de vélo.
Comme nous en possédons beaucoup, la recherche est paginée pour éviter les lenteurs. Il est possible de rechercher un vélo par son matricule, sa batterie, son statut, son modèle où l'adresse de la station à laquelle il est rattaché.
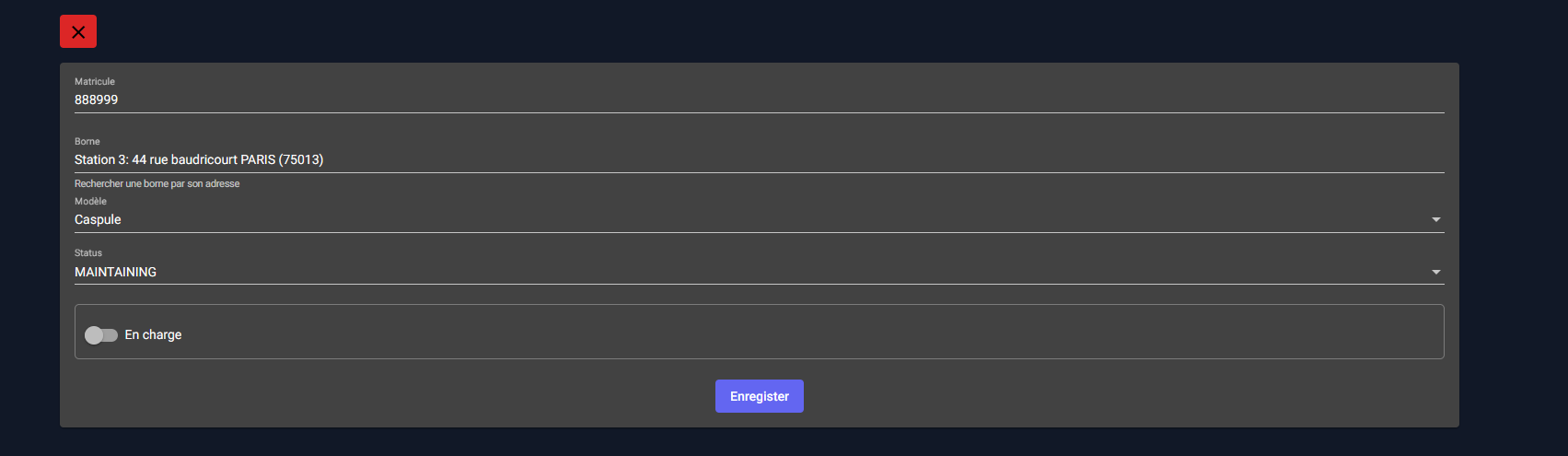
Ajout et modification d’un vélo
L'interface d’ajout et modification d'un vélo sont sensiblement les mêmes, à la différence près que lorsqu'on modifie un vélo, les champs sont déjà pré-remplis.
On peut ainsi modifier son modèle, la station à laquelle il est rattaché et d'autres informations.
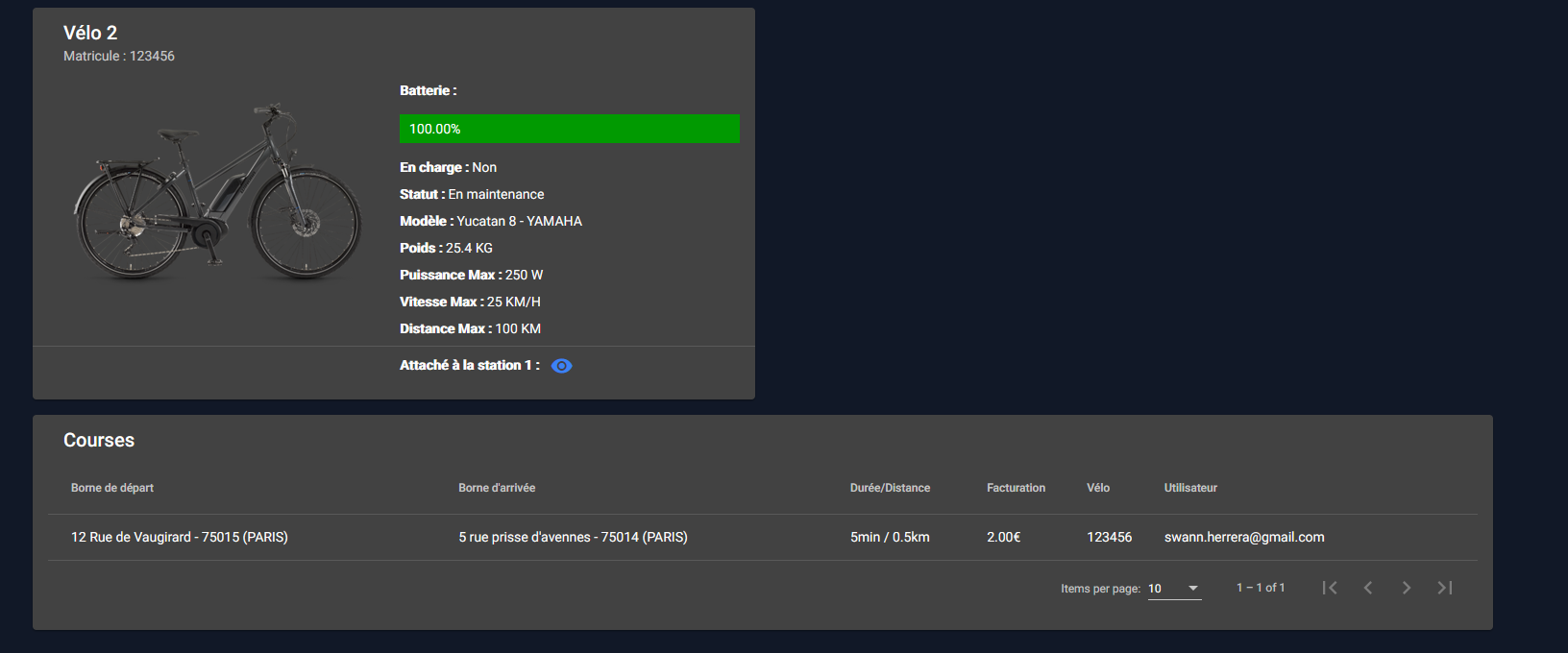
Consultation d’un vélo
Consulter un vélo permet de voir son état général ainsi que la station à laquelle il est attaché.
On peut également voir les courses qui ont été effectuées avec celui-ci.
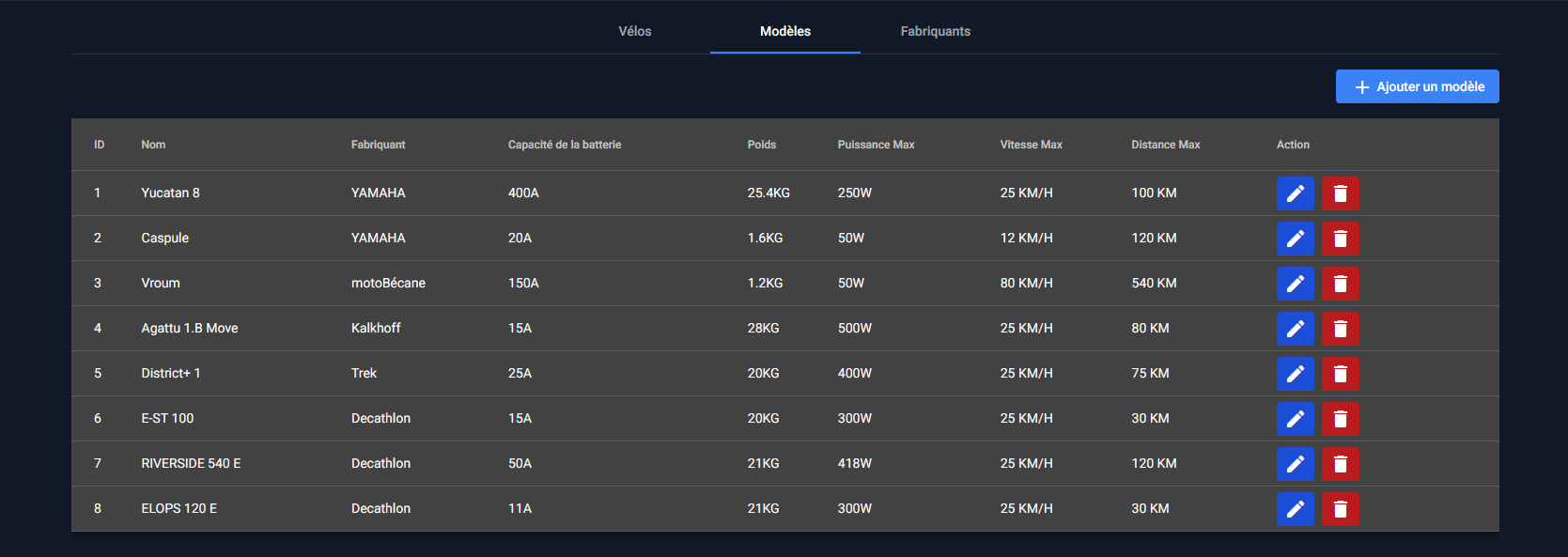
Gestion des modèles
Un vélo appartient avant tout à un modèle qui est administrable au sein de Vécolo.
On peut configurer le nom du modèle, son fabricant, et d'autres informations spécifiques au vélo. On peut aussi ajouter une image pour celui-ci.
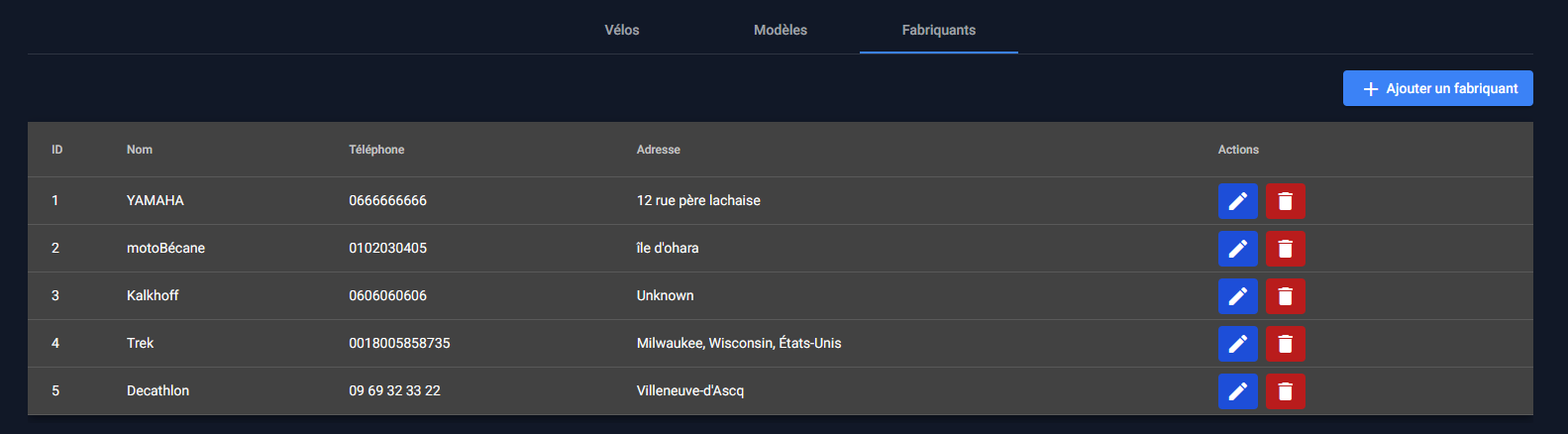
Gestion des fabricants
Pour pouvoir ajouter un modèle, il faut spécifier son fabricant, chose qui est également administrable dans Vécolo.
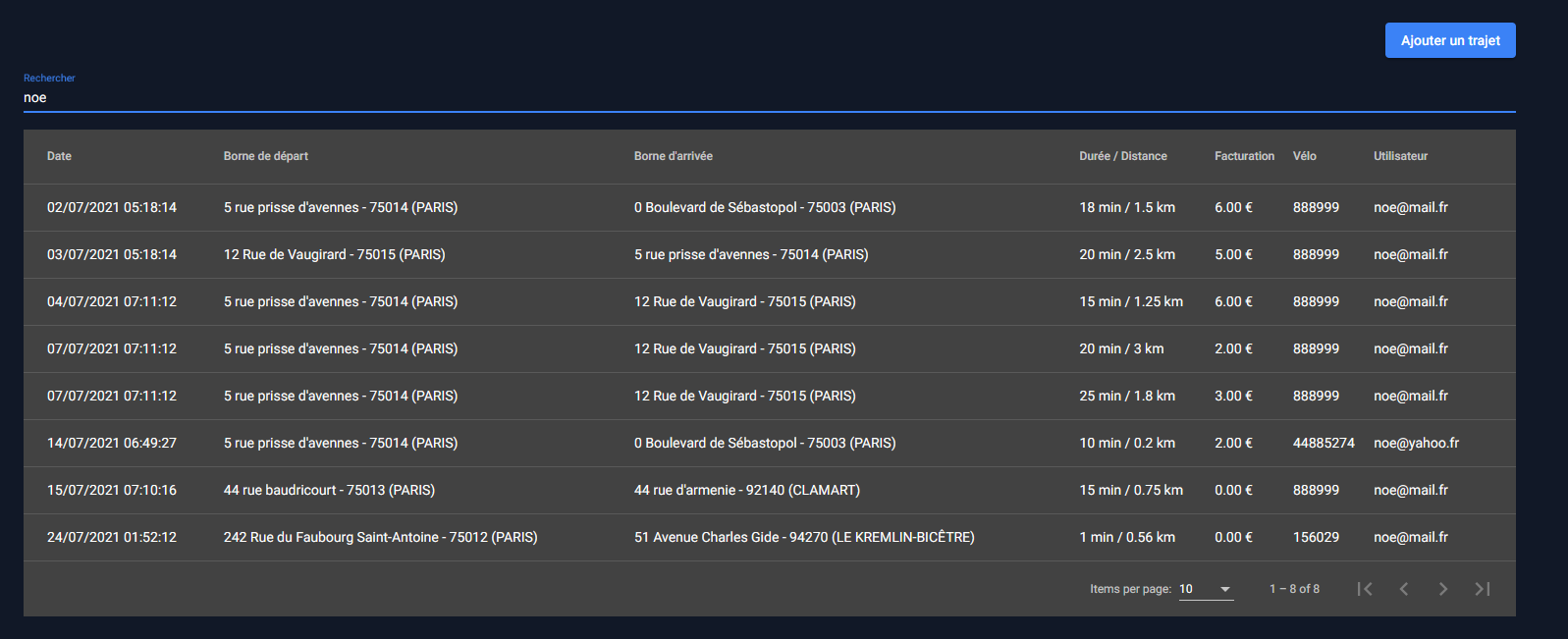
11. Trajets (Staff)
Liste des trajets
Les membres du staff peuvent consulter tous les trajets qui ont été effectués sur l'application.
Là aussi les données sont paginées et recherche able à l'aide d'un champ unique qui va chercher sur toutes les informations visibles dans le tableau.
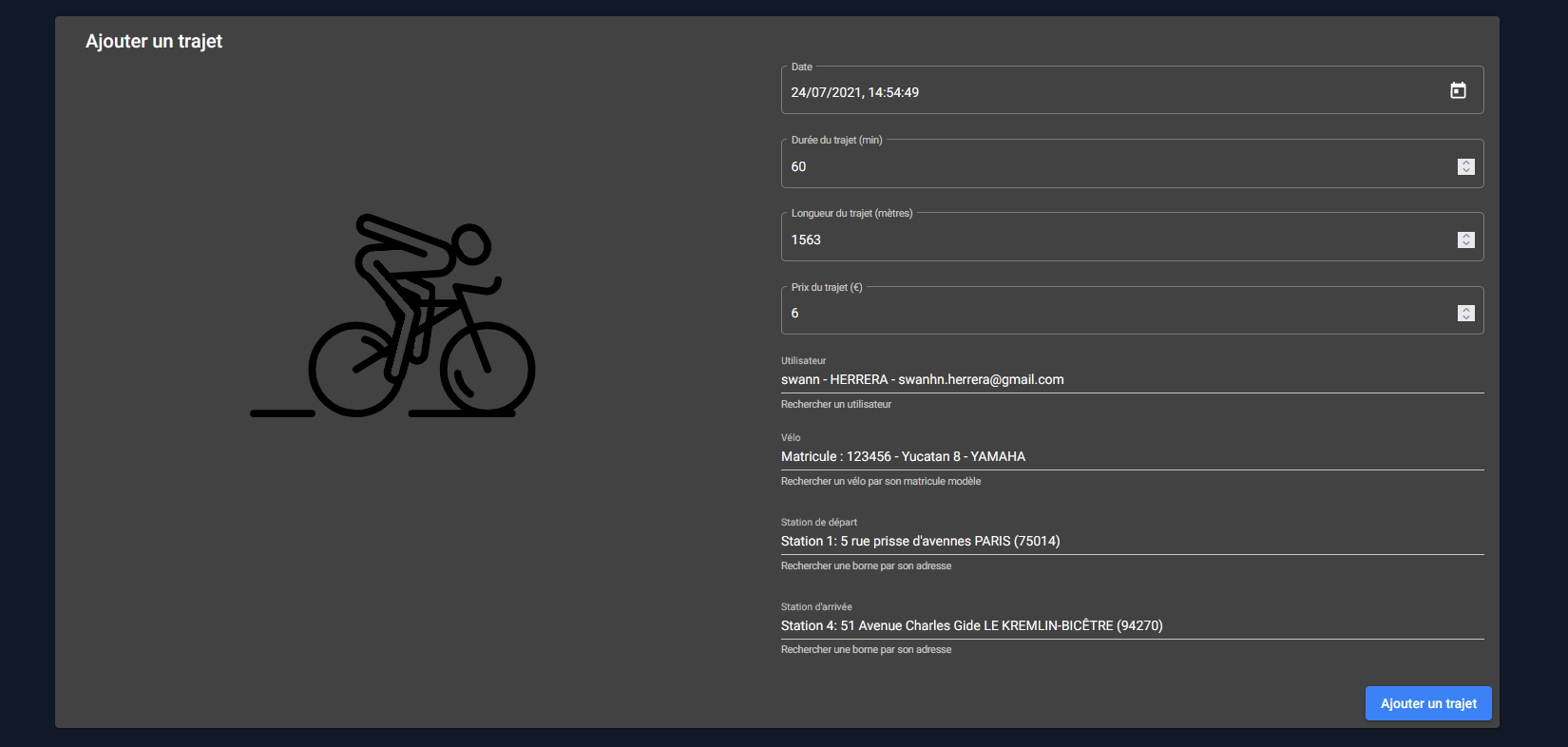
Ajout d’un trajet
On peut ajouter soit même un trajet dans Vécolo. Pour cela il faudra renseigner tous les champs nécessaires à un trajet qui est terminé.
Cette interface possède beaucoup de champs d’auto-complétions qui vont aller chercher des données présentes en base en temps réel
Consultation et modification d’un trajet
Un utilisateur peut accéder à ses trajets au travers de son profile, mais les membres du staff peuvent quant à eux supprimer, modifier et consulter les trajets de n’importe quel utilisateur.
12. Abonnements et forfaits (Staff)
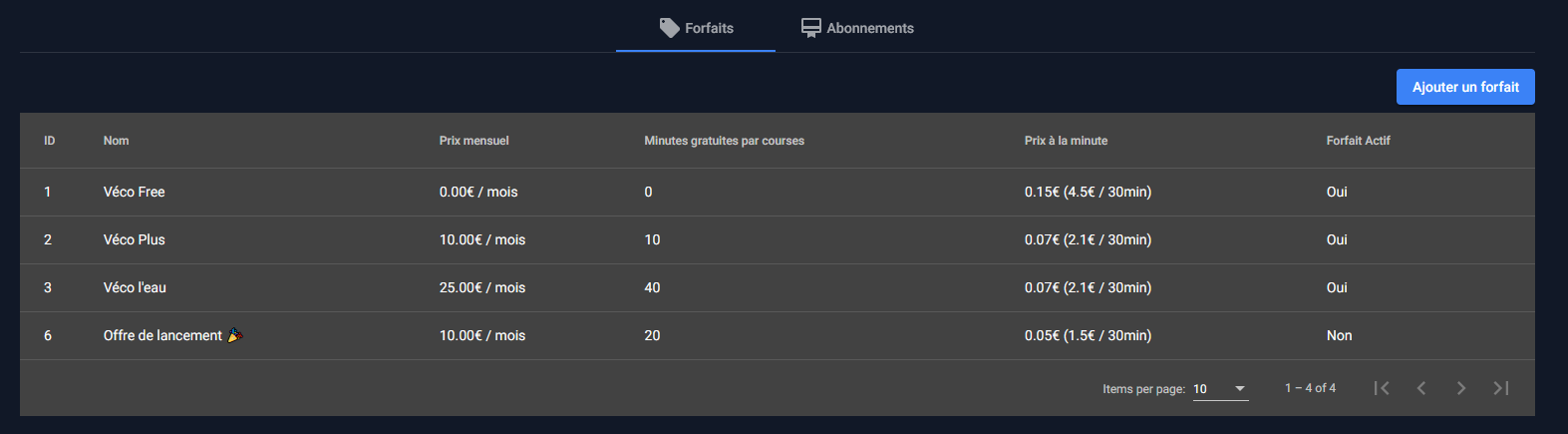
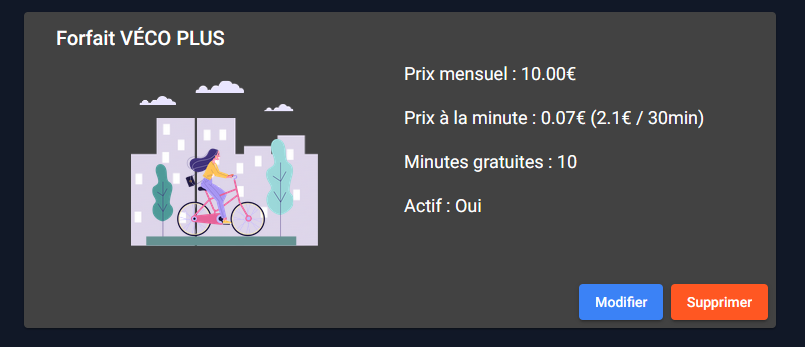
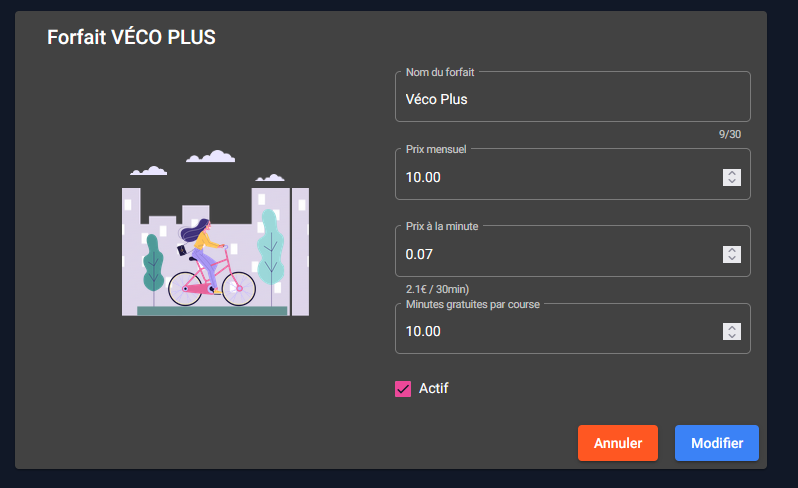
Gestion des forfaits
Les membres du staff peuvent administrer les différents forfaits mise à disposition sur Vécolo (seuls les administrateurs en revanche peuvent les supprimer). Un abonnement peut être marqué inactif si celui-ci ne doit pas apparaître côté client.
 |
 |
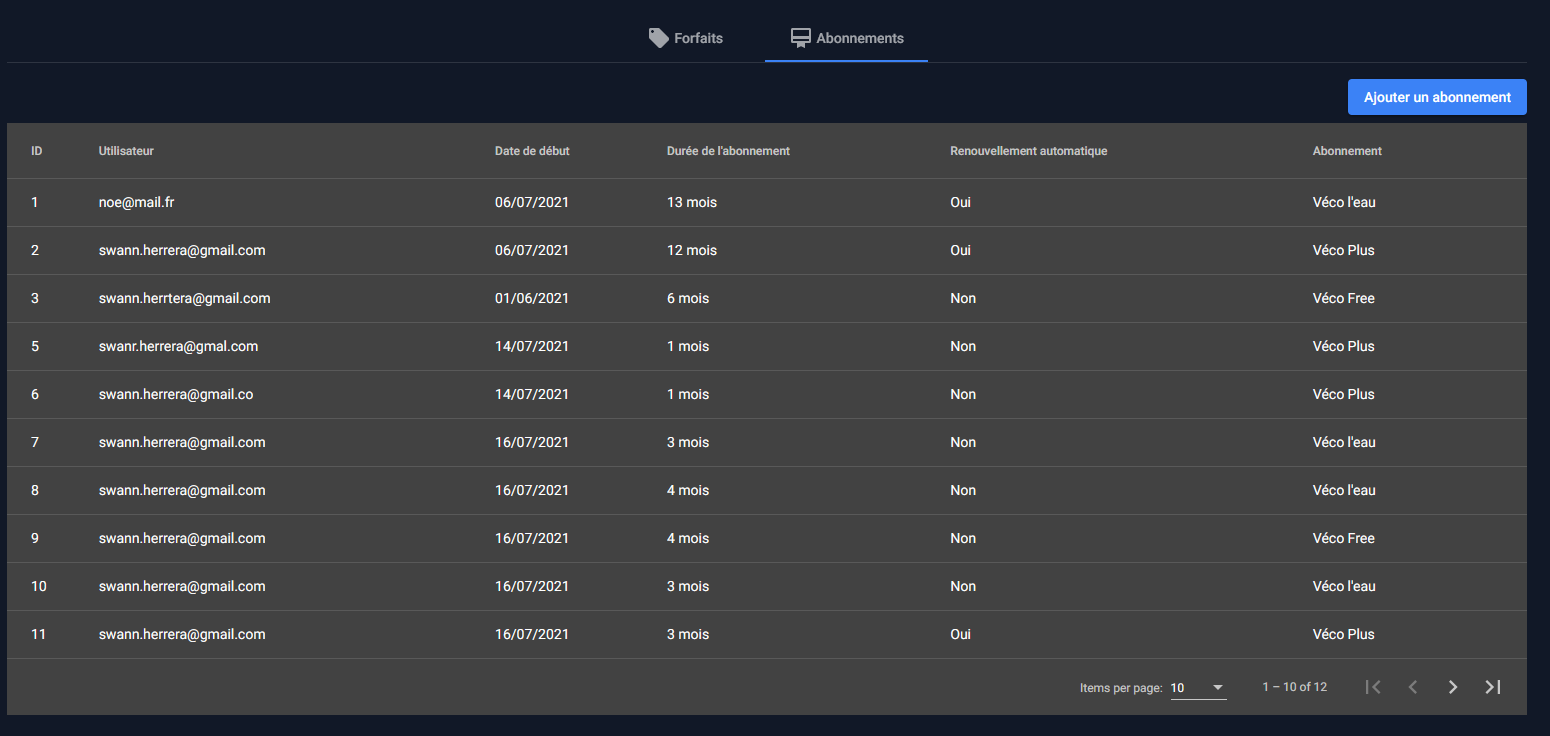
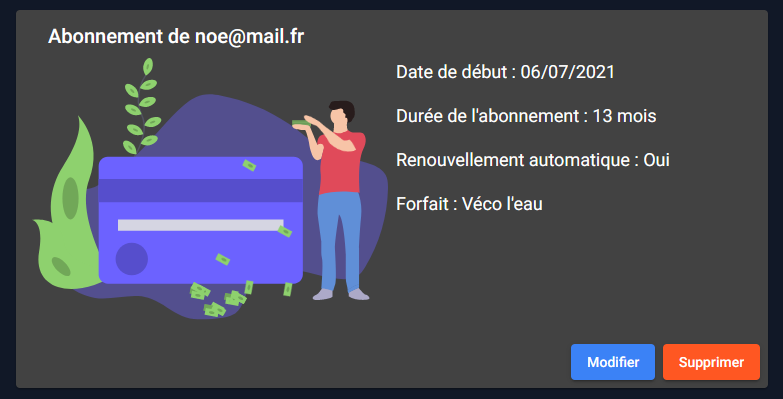
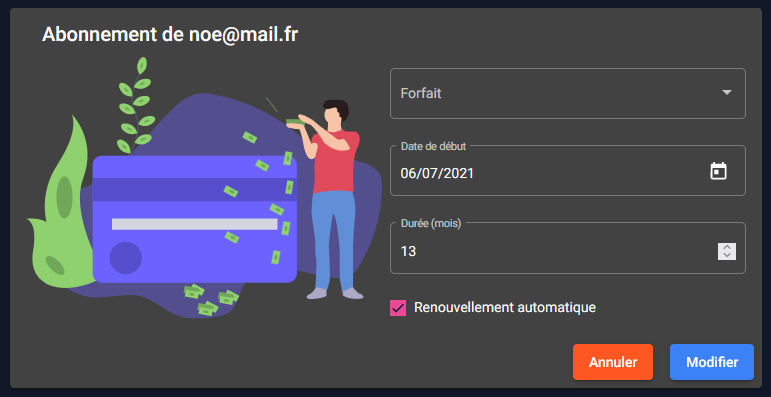
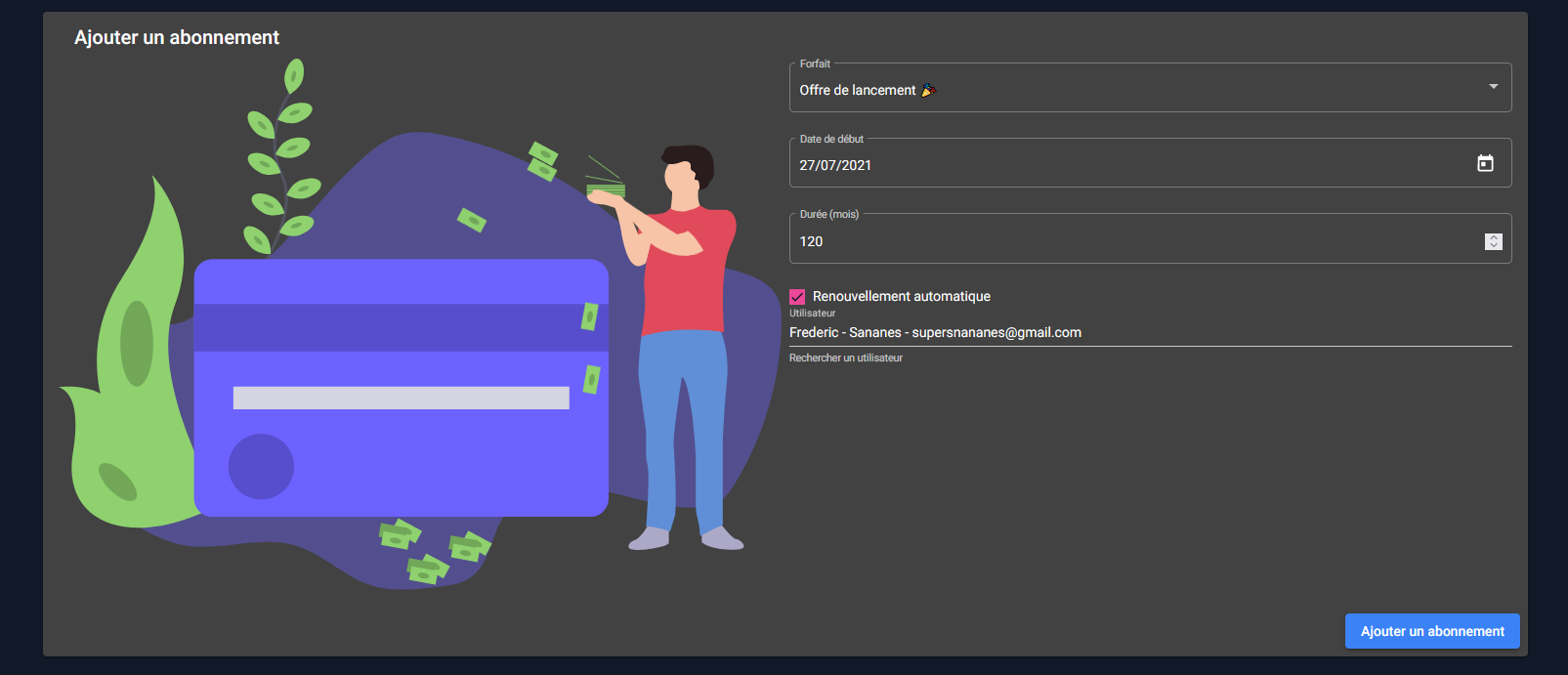
Gestion des abonnements
Les membres du staff peuvent bien entendu interagir avec les abonnements pries sur l'application par les clients et les modifier à leur guise.
 |
 |
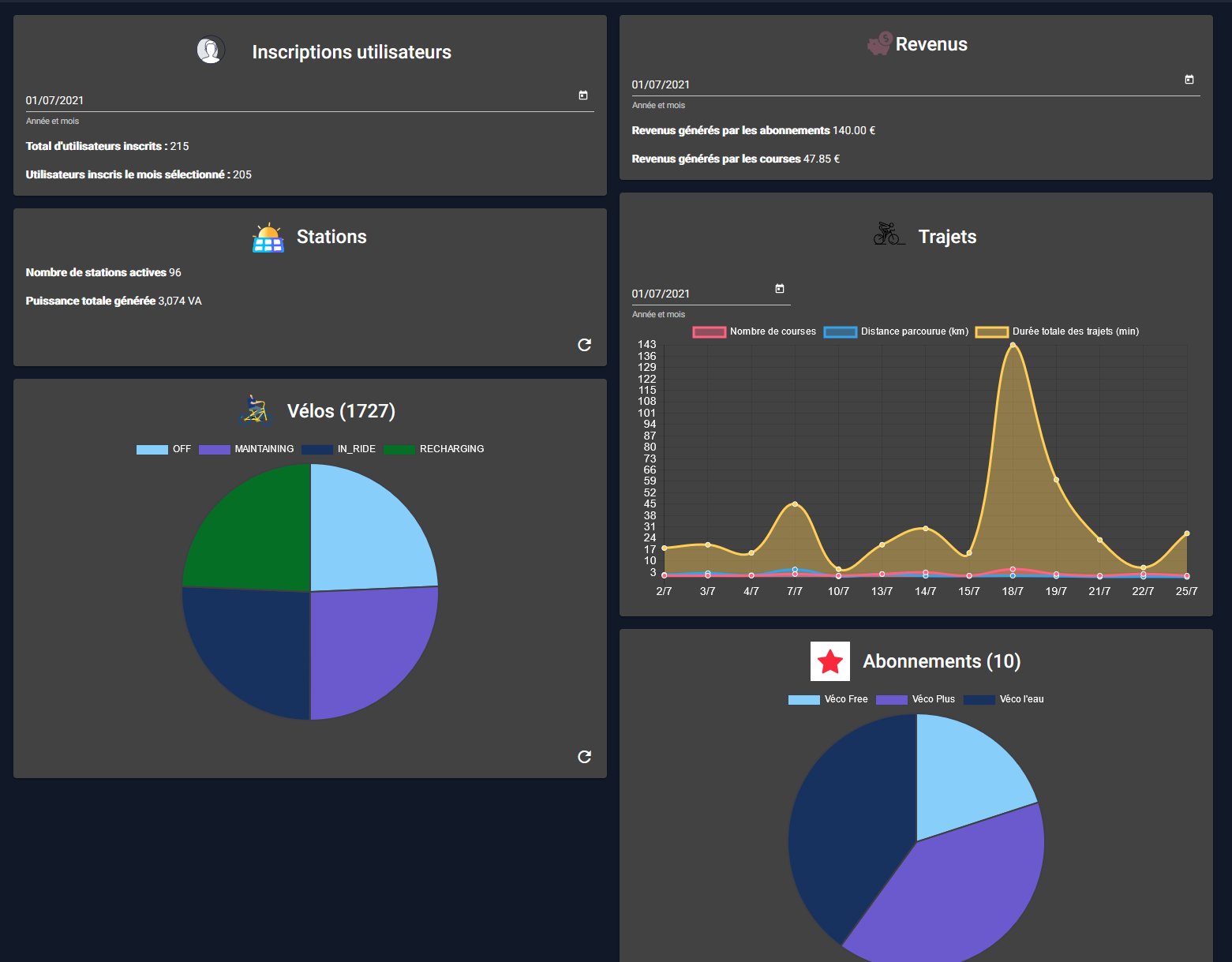
13. Statistiques (Staff)
Les statistiques sont réservées aux membres du staff. Il s’agit d’une page qui permet de consulter l’évolution de Vécolo au fur et à mesure du temps.
Elle est constituée de 6 sections :
· La première permet de suivre les inscriptions utilisateurs à travers le temps et le nombre total d’inscrits
· La deuxième concerne les revenus de Vécolo
· La troisième concerne les stations actives et la puissance développée
· La quatrième concerne les trajets
· La cinquième est pour les vélos
· La sixième concerne les abonnements.
III. Choix d’implémentations
1. Architecture du code
La partie Core de l’application
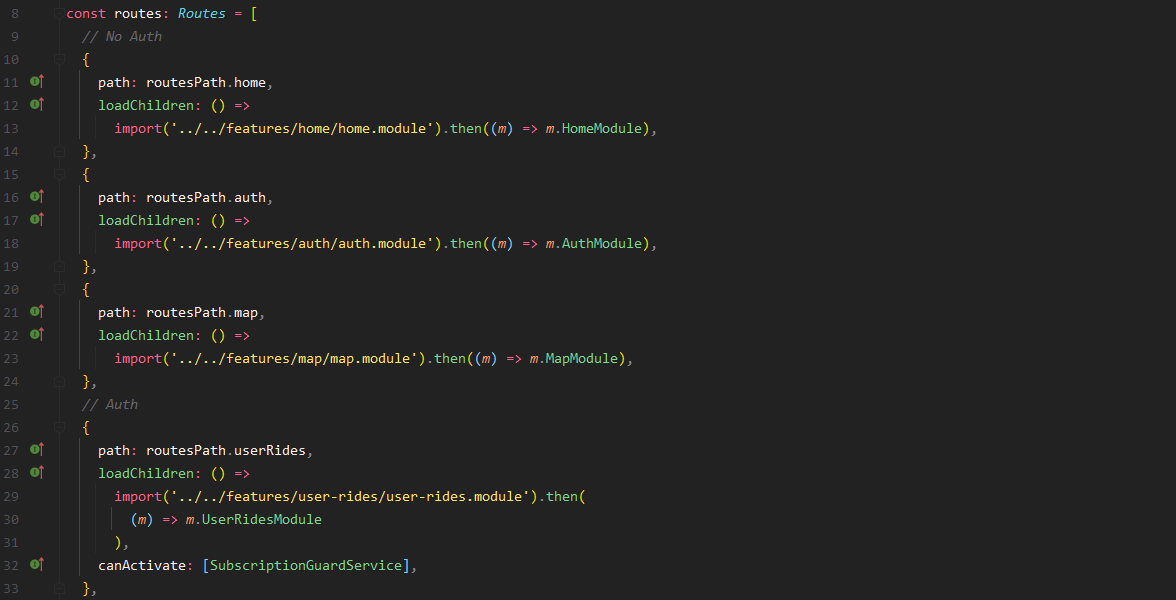
À la racine de la partie « app » du projet nous avons trois dossiers :
· Feature
· Core
Le code qui est dans le dossier Core, est le code qui est essentiel au bon fonctionnement de l’application. On y retrouve par exemple les « Guards » qui restreignent l’accès à certaines parties de l’application.
Les Guards
Dans notre cas on utilise un Guard par rôle (on omet le rôle des stations ici) et un autre pour les utilisateurs avec un abonnement actif.
Ces « Guards » sont utilisé partout dans l’application de manière implicité car même si chaque Feature a son propre routage ; pour définir ses sous-routes, c’est en général dans le router principal qui est dans Core que l’on utilise ces Guards pour sécuriser les routes.
Dans le cas où nous tentons d'accéder à une route nous ne sommes pas censés aller, nous sommes automatiquement redirigés sur la page d'accueil ou de connexion.
Le système de Routing
Nous possédons un routeur principal dans le module Core, qui va rediriger les chemins principaux vers des sous routeurs qui seront chargés en « Lazy Loading » c'est à dire uniquement lorsque nous tenterons d'accéder à celui-ci. Cela permet pour les clients de ne pas charger les parties administrateur, et de gagner un peu de temps au chargement initial.
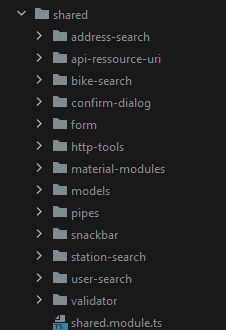
Le module Shared
|
L'intérêt d’Angular est de pouvoir réutiliser des composants à différents endroits. Cependant avec le système de modules de Angular cela peut vite devenir fastidieux car les imports sont longs. Pour nous simplifier la tâche nous avons un module « Shared » qui va se charger de ça pour nous et d'importer en une fois tous les composants partagés. Il suffira alors uniquement d'importer ce module-là dans les endroits de l'application nous souhaitons utiliser des composants partagés. C’est notamment le cas des composants Angular Material, mais aussi des formulaires de recherche des models ... Toutes ces parties de l’application qui sont soit réutilisables et utilisés à large échelle sans pour autant être au cœur du projet sont mis dans le module « Shared ». |
 |
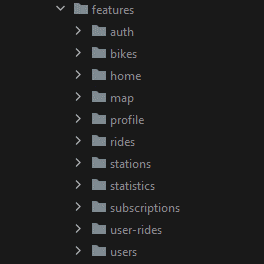
Séparation du code par « Feature »
|
Dans le projet, chaque fonctionnalité « métier » est groupée au sein d’une Feature. Une Feature a son propre data store et on évite d’utiliser des composants qui sont dans une autre Feature. On passera plutôt par les composants partagés. |
 |
L’architecture composant container
Pour ce projet, nous avons souhaité partir sur une approche composant container, dans laquelle toutes les actions sur le store, s’ont mises au sein des container et on donne au composant enfant, juste de quoi lancer la fonction du composant parent.
Nous avons utilisé cette approche pour maximiser l’aspect réutilisable des composants.
Donc, on va chercher à ce que le composant n’ait pour scope que lui-même.
Le data store d’Akita
Pour ce projet, nous avons décidé de partir sur une architecture avec un datastore.
Dans notre cas, on se sert de la librairie Akita pour gérer le store global. Celle-ci se repose elle-même sur la librairie RxJS.
Dans cette librairie, il utilise plusieurs types de store qui seront de toutes façons fusionnées dans un store global.
Le Store est géré par 3 composantes principales :
· Le Store en lui-même qui va servir à stocker la donnée
· Le Query qui ira récupérer la donnée en tant qu’observable
· Le service qui appellera les avis et modifiera la donnée
2. Technologies utilisées








IV. Dossier d’installation
Prérequis
Pour installer l’application il est nécéssaire d’avoir installé nodejs, npm et ng (npm i -g ng)
Pour installer l’application il suffit de cloner le projet (git clone https://github.com/vecolo-project/vegular.git)
Ensuite il va falloir faire un npm i pour installer les dépendances. Par la suite, il faudra lancer l’application. Pour la lancer en mode développement, il faut faire soit npm start ou alors ng serve.
En production l’application n’a pas besoin d’être délivrée par NodeJS, elle a juste besoin d’être accessible depuis un serveur web. Pour ceci nous vous recommandons d’utiliser docker. Et je vous renvoie vers la documentation d’architecture.
Pour que l’application puisse bien fonctionner, elle a besoin d’être lancée avec l’API. Pour ceci, vous trouverez dans le dossier src/environnements, le moyen de la connecter au backend de votre choix.
Une version Docker de l'application existe, elle peut être construite directement à partir du code source
V. Bilan du projet
1. Problème rencontres
Prise en main
Il y a eu un vrai temps d’adaptation pour ce projet que ça soit avec Akita, Angular Material ou Angular tout simplement ce sont des technologies pas très intuitive parfois mal documentés.
Architecture du projet et datastore
Le projet a mis énormément de temps à démarrer car beaucoup de temps a été passé sur la mise en place de l'architecture du code. Nous avons recommencé plusieurs fois car nous voulions quelque chose de cohérent et robuste avec toutes les technologies que nous implémente ions à l'intérieur. Il a fallu près de 2 semaines entières pour arriver sur le code qui sera la base de notre projet.
Les champs autocompletes
On a eu aussi beaucoup de mal à mettre en place les champs autocomplète d’Angular Material, notamment quand le rendu ne pouvait pas être géré en front par l’application et que l’on était obligé de passé par l’API. De plus, ces champs d’auto-complétions font souvent partie de formulaires et il a fallu bien gérer son remplissage.
Le module http d’Angular
Pour les modèles des vélos nous avons mis en place un upload de fichier pour mettre à jour l’image ou l’ajouté.
Nous avons eu beaucoup de mal à le mettre en place.
Angular essaye de rajouter la taille du fichier dans l’entête http « content-type » et étant donné qu’on lui donnait explicitement le header il calculait une taille de 0 octets au fichier ce qui était faux et qui était mal compris côté serveur.
Pour résoudre le problème nous avons été obligés de modifier le wrapper du httpClient d’Angular et de crée une méthode d’upload qui ne remplis aucun content type pour qu’Angular puisse lui-même calculer la taille du fichier et la mettre dans le header.
Les erreurs d’Angular
Ce dernier problème est un problème plus général c’est que parfois les erreurs d’Angular sont incompréhensible.
Parfois il ne nous donne pas l’endroit de l’erreur, parfois c’est le message qui n’est pas explicite. Et quand l’erreur et dans le template Html l’erreur n’est tout simplement pas afficher du tout.
2. Conclusion
Ce projet et l’un des projets qui s’est le mieux passé car nous avons pu l’anticiper.
Nous avons beaucoup travaillé ensemble dessus, en même temps face à face et ça nous a beaucoup aidé à prendre de bonnes habitudes grâce au retour de l’autre. C’est aussi le projet qui nous a pris le plus de temps et que l’on n’a pas forcément trouvé le plus agréable car les technologies sont un peu lourdes.
Pour conclure nous sommes très contents de ce projet, nous pensons que Angular est une technologie qui a ses défauts mais aussi beaucoup d’avantages notamment la rigidité de sa structure. Cette application a fait office de beaucoup de risque car avec le recul et le cours sur l’agilité nous remettons en cause l’ordre dans lequel nous avons réalisé les fonctionnalités. Nous aurions aussi travaillé beaucoup plus en symbiose avec le développement de l’API.
Vékanban
I. INTRODUCTION
1. RAPPEL DU SUJET
Pour notre projet annuel, il nous a été demandé de concevoir une application Java. Cette application doit être un client lourd , possédant une interface graphique de type JavaFX. Elle devra avoir pour but de gérer l'équipe de développement du projet (gestion et définition des tâches, planification, affectation de ressources humaines aux tâches, gestion de tickets...). Un système d'extension de type Plug-in devra être présent. Il faudra vérifier que le plug-in pouvant être construit par 1 tier possède bien la liste des fonctions attendues et que celui-ci s'intègre à l'application sans recompilation. Une gestion des différents plugins devra être intégrées dans l'interface.
2. APPLICATION CHOISI
Nous avons choisi de réaliser une application de gestion de projet agile à l'aide de la méthode Kanban. Elle permettra à l'équipe de développement , ainsi qu’aux consultants de suivre l'avancement du projet. Cette application se comportera exactement comme un Trello. Elle permettra de gérer différents projets, la gestion des tâches à faire, en cours et terminé ainsi que les personnes assignés à ces dernières. Il faudra pouvoir gérer également les dates d'échéance. Pour l'implémentation du plug-in, nous avons pensé un plug-in permettant d'importer les tâches d'un projet Github au sein même de notre application.
II. Focus sur l’application
1. Connexion & Inscription
ConnexionPour pouvoir utiliser l'application, il faut posséder un compte sur celle-ci. Il suffit ensuite de se connecter en indiquant son pseudo et son mot de passe. |
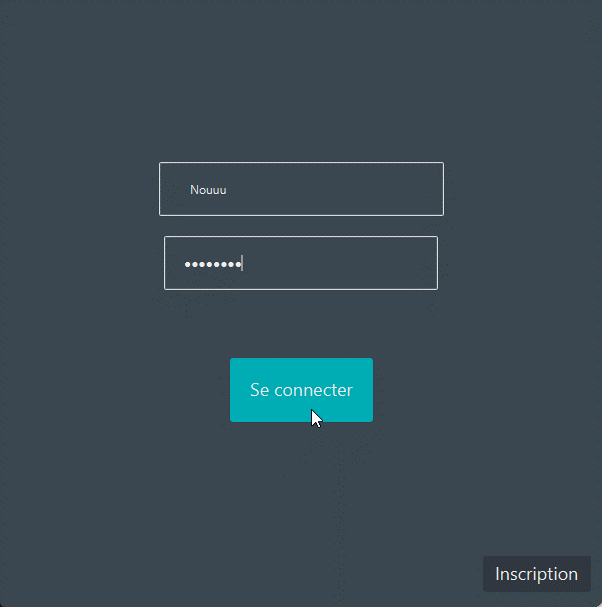 |
Inscription
Il est possible de s'inscrire directement depuis l'application. Pour ce faire il suffit de cliquer sur le bouton inscription qui se situe sur la page de connexion. |
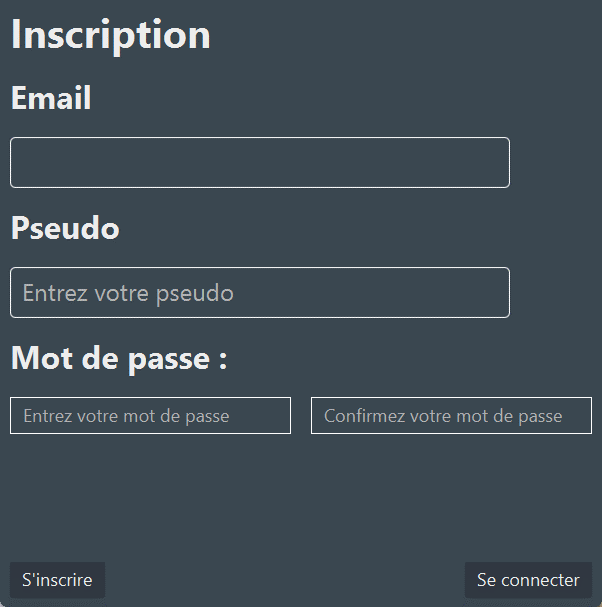 |
Déconnexion
Il est possible de se déconnecter de l'application grâce au bouton log out présent en bas à gauche du menu.
2. Mes projets
Sur cette page, il est possible de voir les différents projets que nous avons créés ainsi que ceux auxquels nous avons été invités par d'autres.
Liste de mes projets
La première ligne affiche les projets que nous avons créés. Il est possible depuis ici de supprimer le projet.
Partagé avec moi
La 2e ligne affiche les projets auxquels nous avons été invités et pour ceux-ci il n'est pas possible de les supprimer, car seule le propriétaire a le droit de le faire.

3. Nouveau projet
Lorsque nous arrivons sur l'interface de création d'un projet, plusieurs champs sont à remplir dont certains obligatoires.
Il faut y renseigner le nom du projet, le préfixe des cartes si l'on souhaite inviter des membres à partir de leur adresse mail (il faut que le membre ait un compte existant sur l'application) ainsi qu'une description. La description prend en charge le markdown.
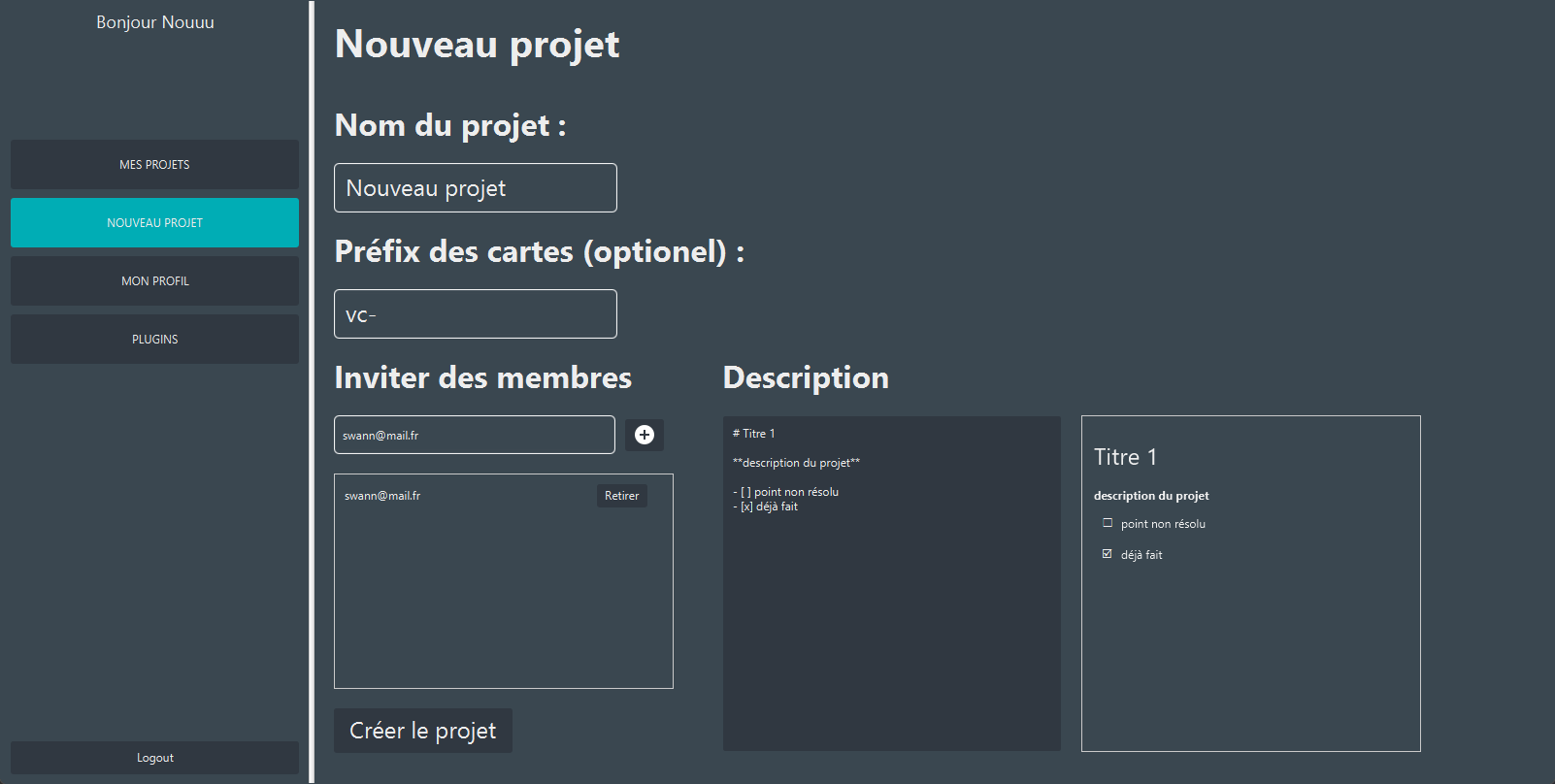
4. Consultation d’un projet
On peut consulter un projet en cliquant dessus depuis, la liste des projets.
Les champs d'administration du projet en lui-même sont réservés aux propriétaires (Nom du projet, description, préfixe et labels.).
Il est possible pour le propriétaire de créer des labels avec des codes couleurs qui pourront ensuite être assignés à des cartes pour une meilleure visibilité.
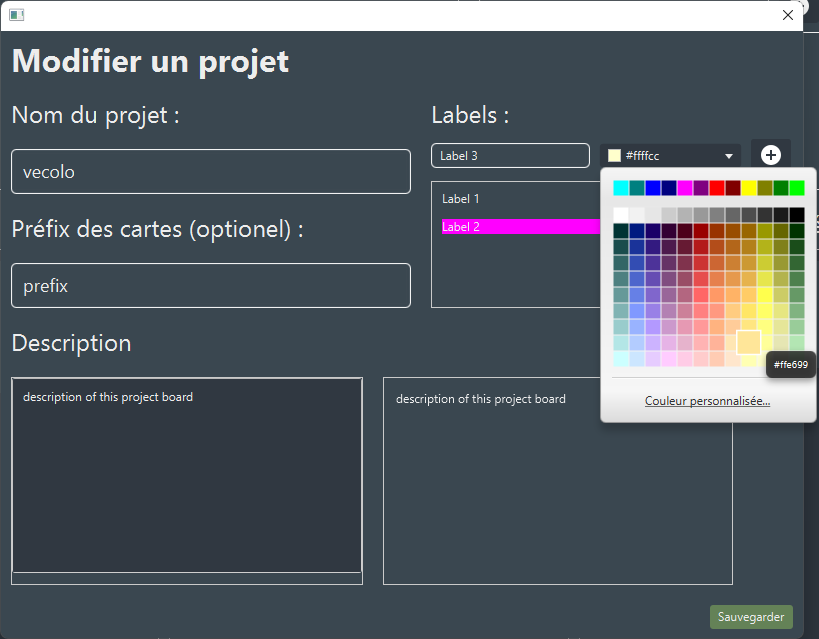
Seul le propriétaire peut inviter où retirer des membres au projet.
On peut consulter sur l'interface le nom du projet, sa date de création, création, sa description, les membres du projet. Ainsi que la liste des tâches.
La liste des tâches est séparée en 3 colonnes. À faire, En cours, Terminé.
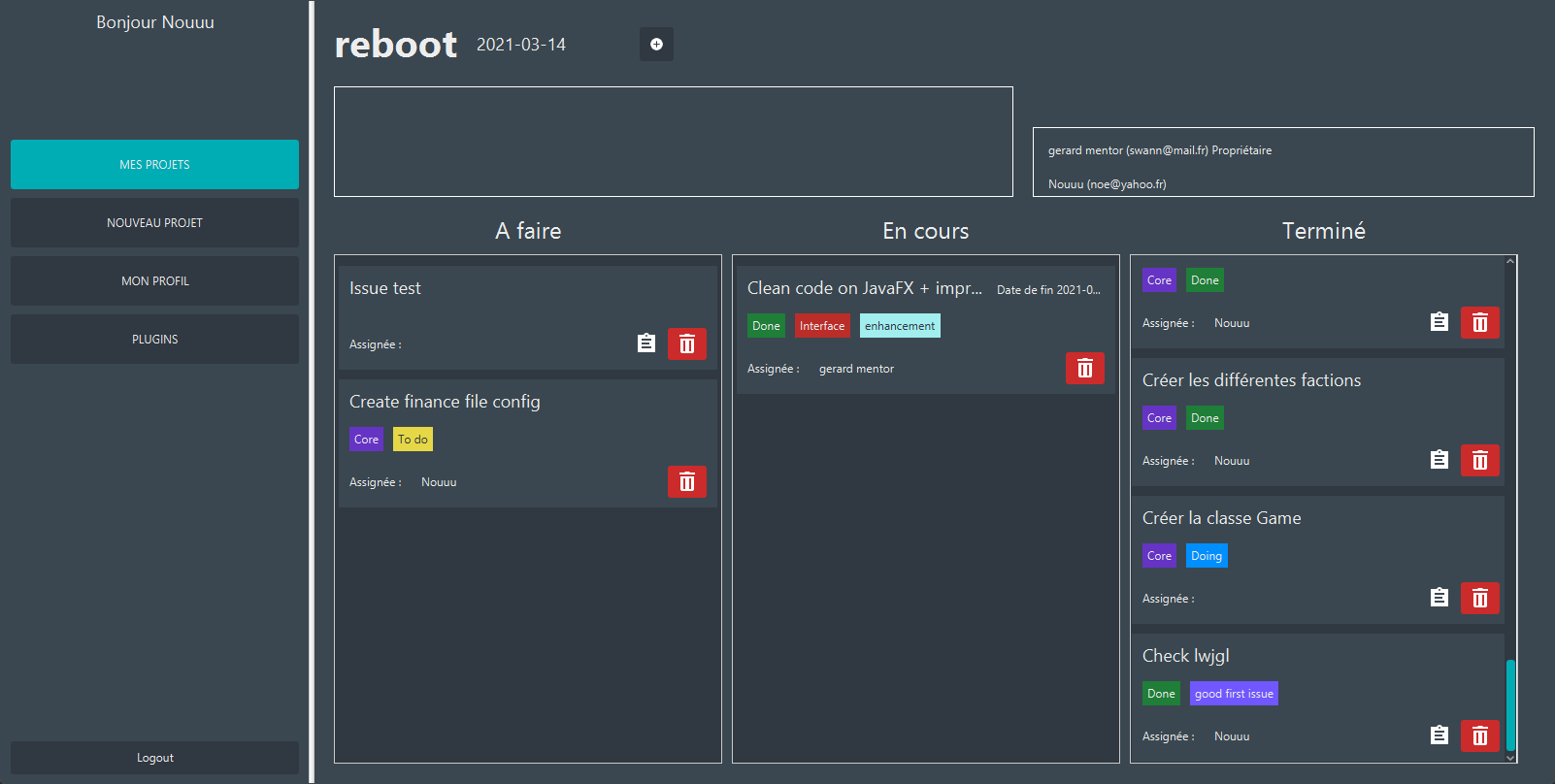
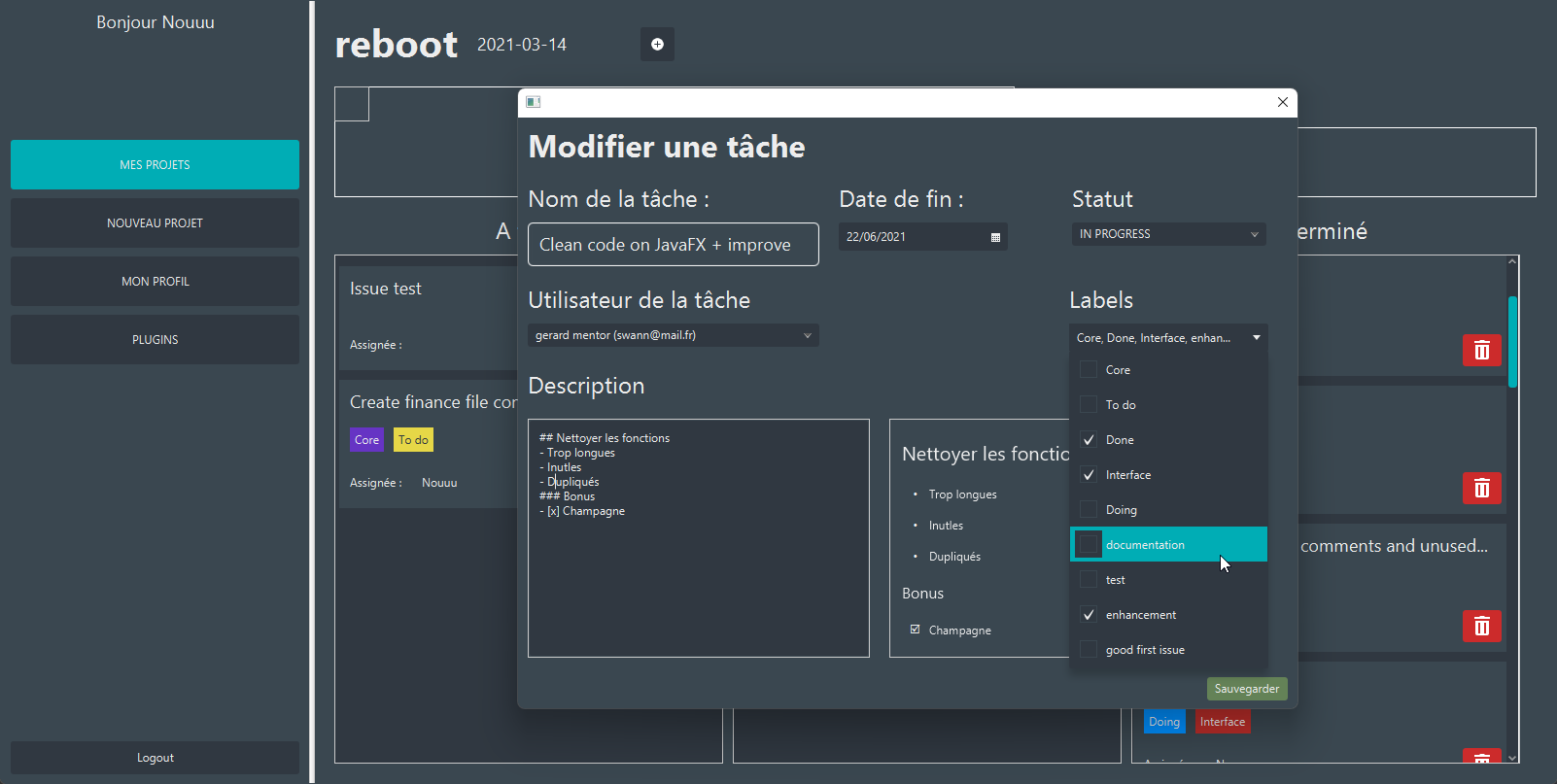
Pour éditer une tache, il faut cliquer dessus. S'ouvre alors une fenêtre depuis laquelle nous pouvons modifier le nom de la tâche, la date d'échéance de celle-ci, son statut, ses différents labels, l'utilisateur assigné ainsi que sa description.
Comme pour la description du projet, la description d'une tâche supporte le markdown.
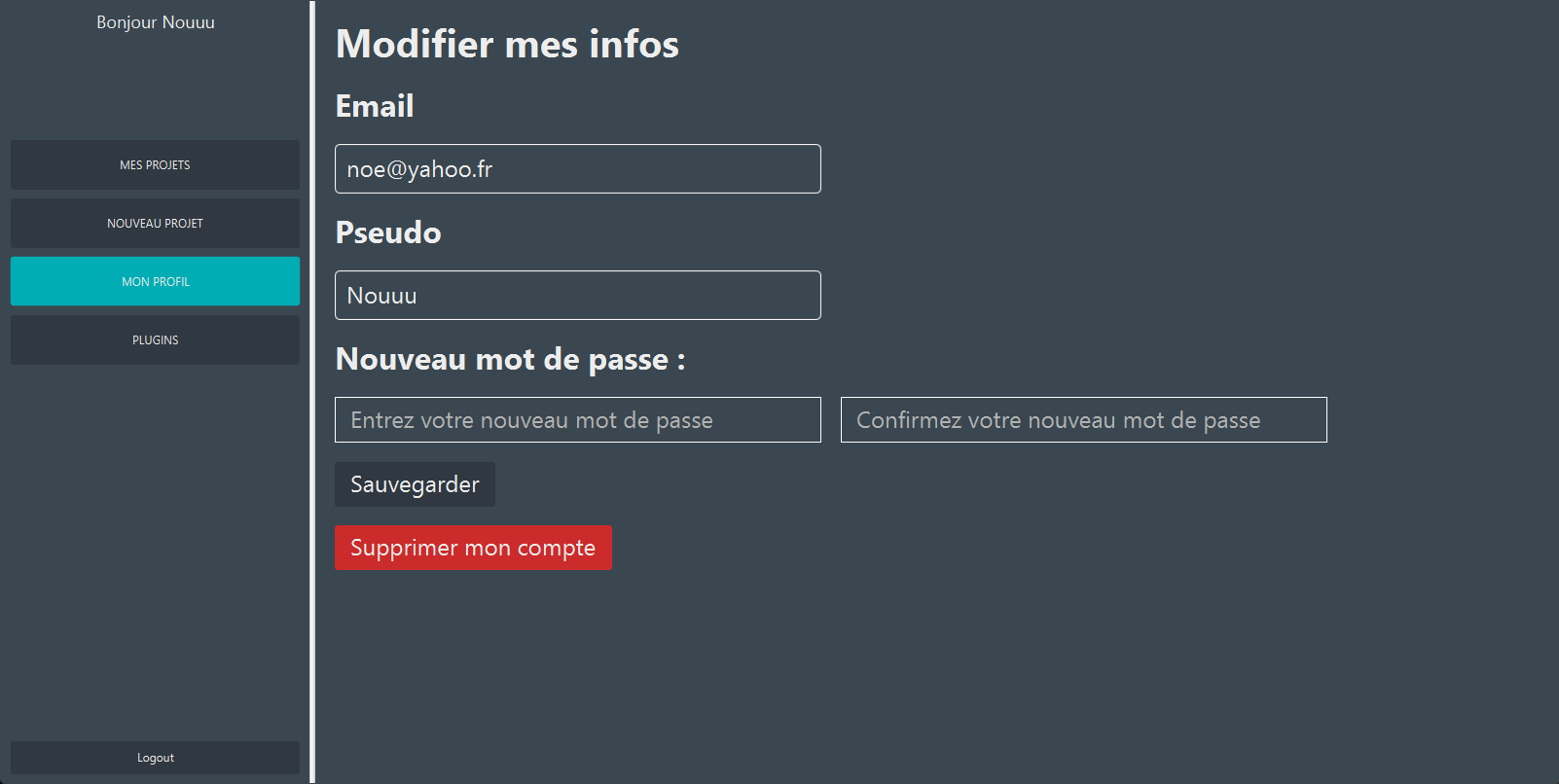
5. Mon profil
L'application permet de modifier ses informations personnelles comme son mot de passe, son adresse mail, ou encore son pseudo.
On peut supprimer son compte. Attention, cela supprimera tous les projets dont on est propriétaire et nous désassignera de toutes les cartes des autres projets.
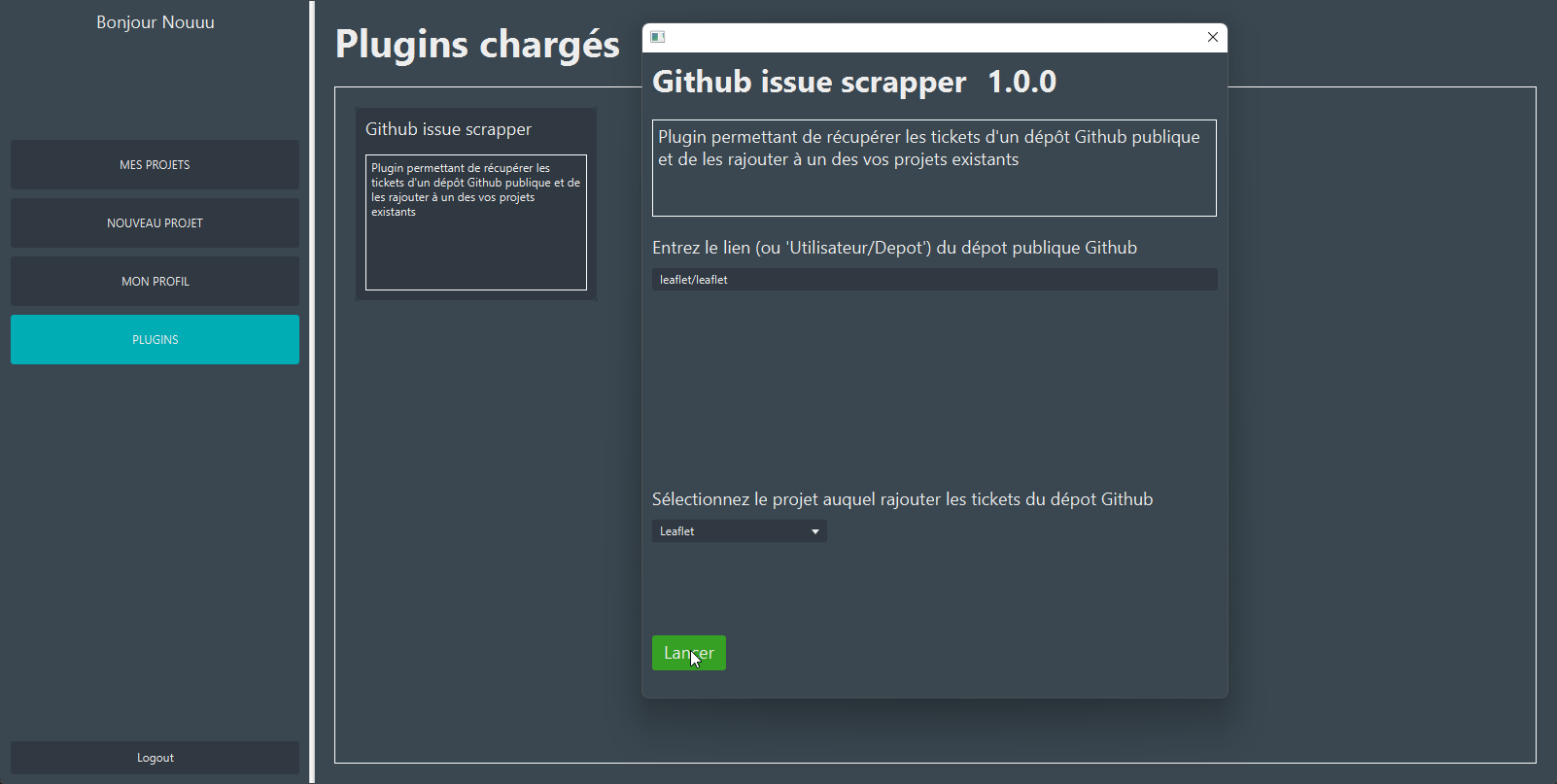
6. Plugins
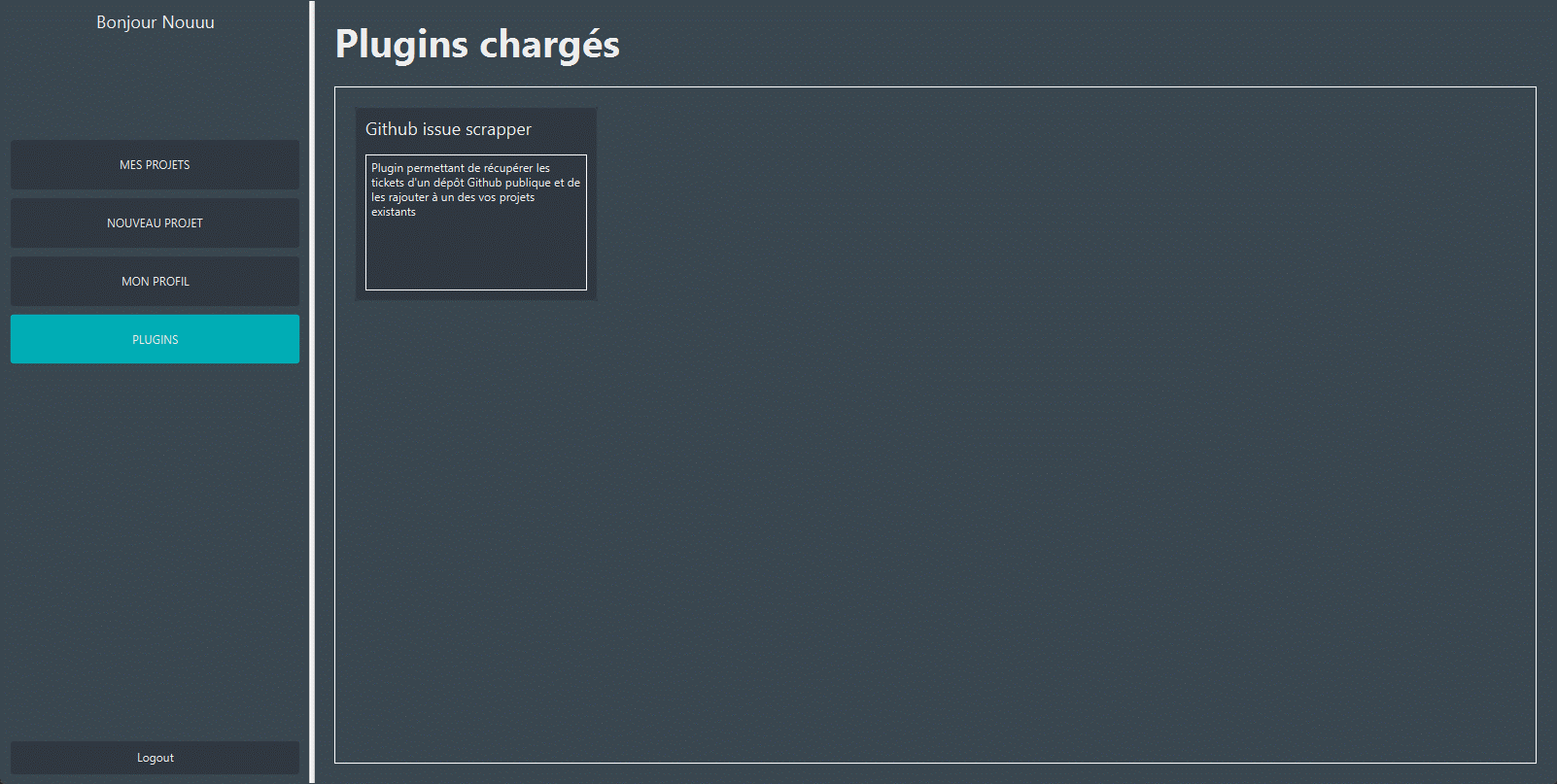
Il suffit ensuite de cliquer sur celui-ci, renseignez les champs nécessaires et le lancer.
Dans le cadre de notre plug-in d'import Github, il faut renseigner le nom du dépôt ainsi que le nom du projet local sur lequel importer les tâches. La fenêtre se ferme automatiquement une fois que la tâche a été effectuée.
III. Choix d’implémentations
11. Technologies et librairies principales utilisées







2. Architecture du code
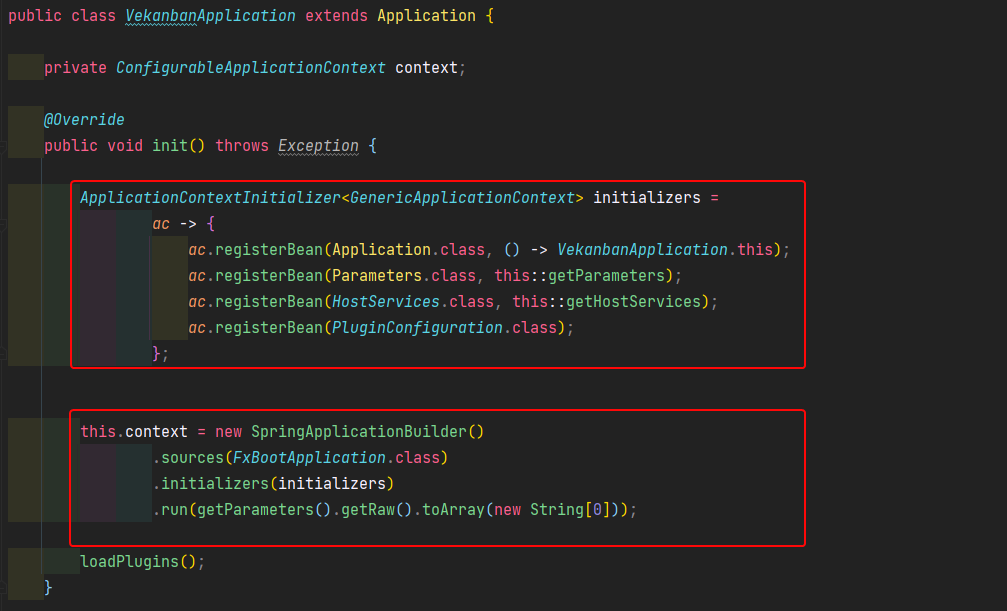
Chargement du contexte Java FX dans Spring
Le point d'entrée de l'application est celui de Spring. Il faut donc lui indiquer dès le départ qu'il doit charger une application Java FX.
Java FX a une classe principale se nommant Application, c'est le point d'entrée.
Nous enregistrons ainsi dans le contexte Spring une seule instance de cette application afin de pouvoir derrière utiliser l'injection de dépendance dessus.
Nous enregistrons également d'autres Bean propre à Java FX afin que tout fonctionne correctement.
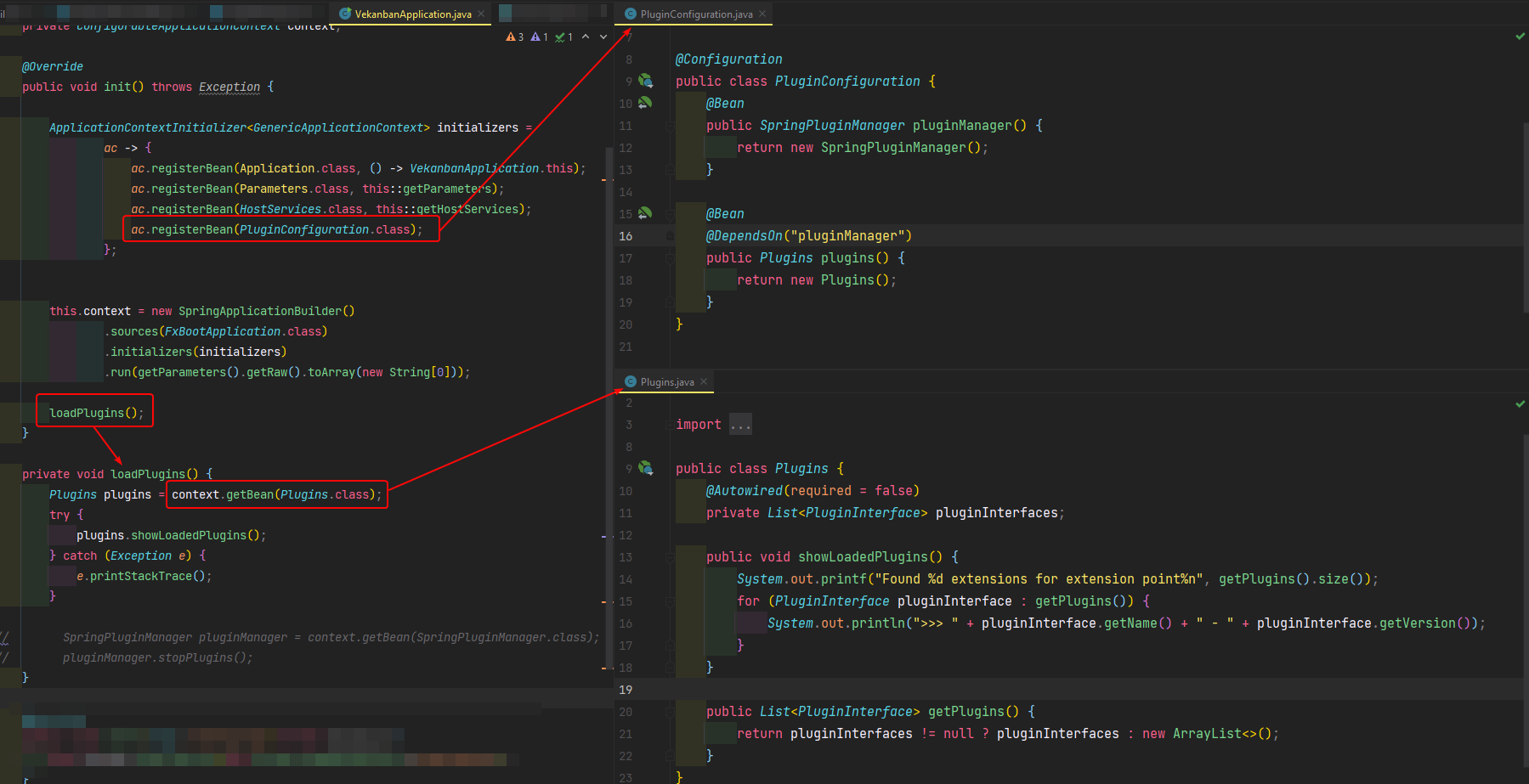
Chargement des Plugins
Les plugins utilisent l'injection de dépendances, ils sont alors eux-mêmes considérés comme une dépendance injectable par l'application principale.
Une fois le contexte Spring chargé au démarrage, ce sont aux plug-ins d'être détectés.
Architecture MVC
L'architecture du projet respecte le modèle MVC (Model, Vue, Controller).
Bien entendu, une adaptation a été nécessaire pour respecter le fonctionnement de Java FX et celui de Spring.
• Nos modèles correspondent aux classes de nos entités (utilisateur, projet, tâche, etc.).
• Nos vues sont les contrôleurs de Java FX qui font l'interface utilisateur.
• Enfin, nos contrôleurs correspondent aux services associés au modèle qui vont effectuer les traitements de données.
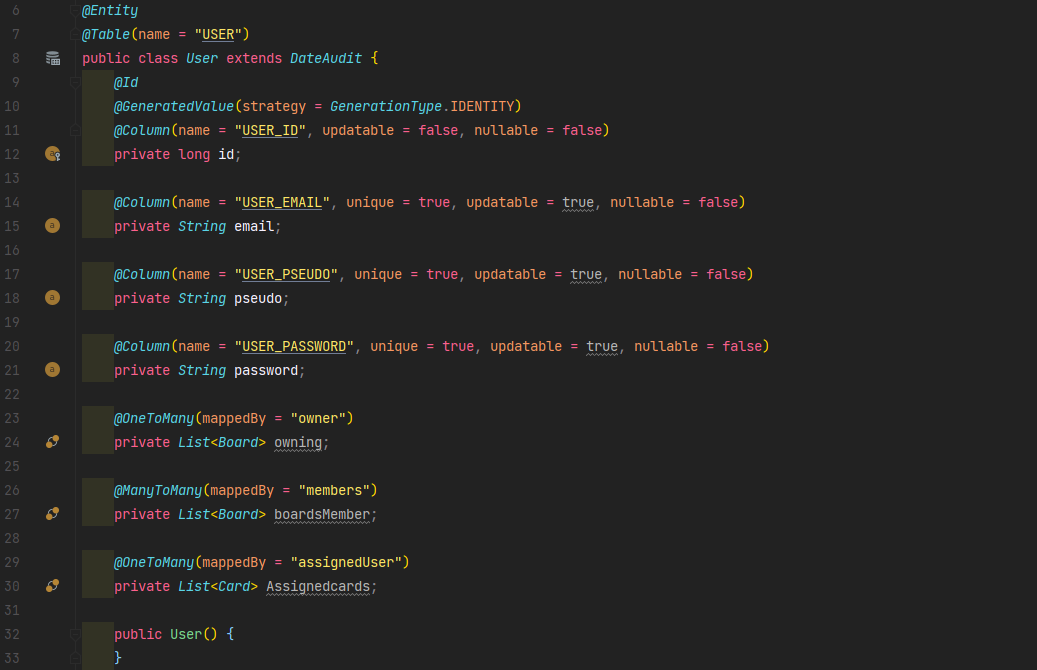
Intégration de l’ORM
Pour intégrer correctement Hibernate, nous avons besoin de 3 types de classes différentes.
• Tout d'abord les entités (ou modèles) qui vont représenter nos tables en base de données et qui correspondent à des objets Java.
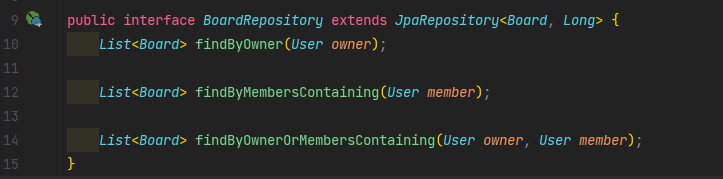
• Ensuite, les repository JPA qui vont être nos interfaces entre nos objets et la base de données, c'est eux qui nous permettront d'effectuer des requêtes.
• Enfin, les services qui vont se charger de traiter la donnée avant de l'envoyer en base ou de la récupérer, ce sont les services qui seront utilisés par les contrôleurs Java FX.
API pour les plugins
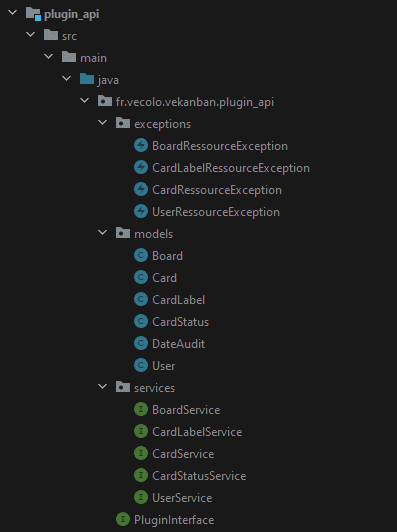
Pour permettre le développement des plugins, un package séparé de l'application principale est mis à disposition pour être importé dans un projet Maven.
Ce package contient uniquement la définition des services par des interfaces, l'interface du plug-in devant être rempli, ainsi que les modèles de classes et les exceptions existant dans notre application.
3. Architecture base de données
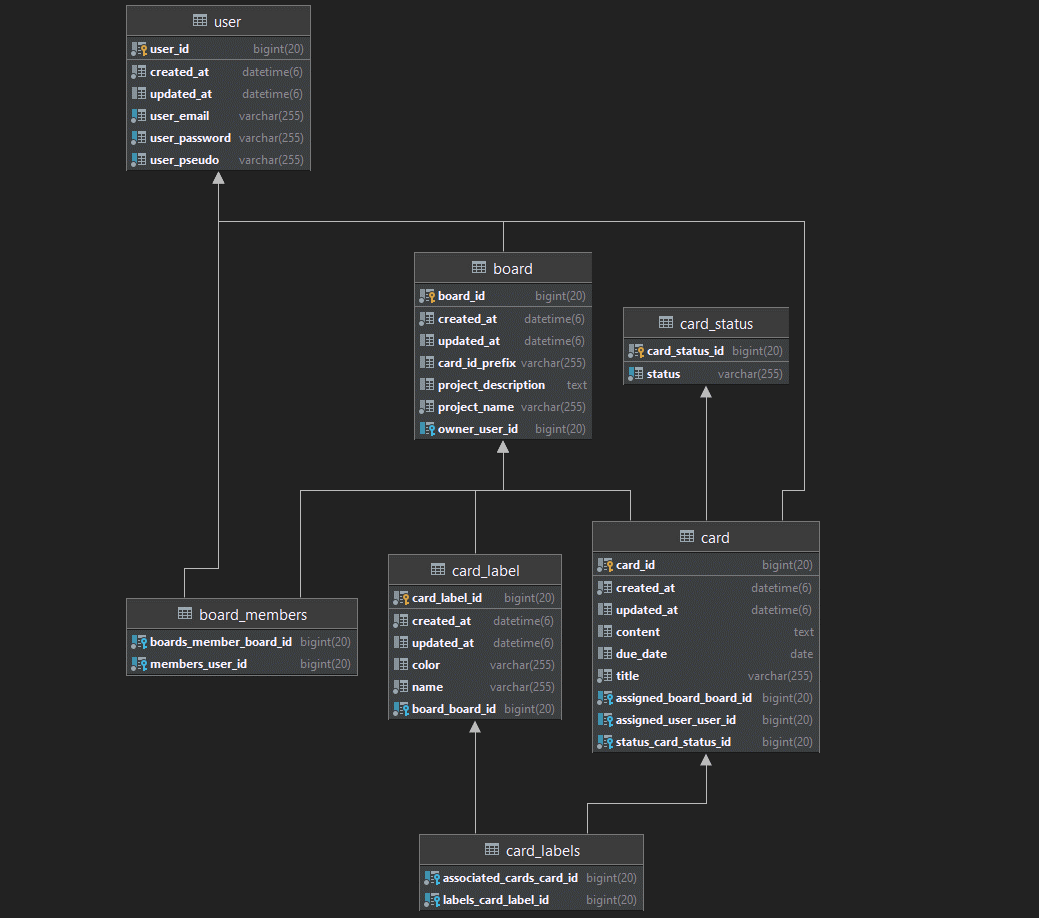
Pour sauvegarder nos données, nous utilisons une base de données MariaDB hébergé en ligne.
Il est possible via le fichier application.properties de changer le driver et de passer sur une base de données PostgreSQL ou même H2 (local).
Voici le schéma de la base de données Vekanban :
IIV. Bilan du projet
1. Problèmes rencontrés
Fusion de Spring Boot et JavaFX
Spring Boot et Java FX n'ont jamais été conçus pour être utilisés ensemble. Le projet a mis donc énormément de temps à démarrer car il a fallu faire cohabiter ces deux Framework ensembles.
Thème sombre de l’application
Les éléments graphiques de Java est fixe son de base claire. Or nous voulions un thème sombre. Il est possible de personnaliser ses composants à l'aide de balises CSS et nous avons dû passer beaucoup de temps à réécrire le thème CSS composants par composants pour avoir un thème sombre qui nous plaisait (500 lignes de CSS au total).
Gestion des différents contrôleurs JavaFX
Puisque nous avions décidé d'intégrer Spring boot, il fallait que les contrôleurs Java et fixes puisse être auto injectés. Cela a posé plusieurs problèmes au début notamment sur les contrôleurs qui devaient être présents en plusieurs instances (les cartes des taches par exemple) carte de base Spring fonctionne avec des singletons. Nous avons pu cependant résoudre cela en utilisant une annotation supplémentaire sur nos contrôleurs (@Scope("prototype")) et tout est rentré dans l'ordre.
Intégration du markdown
Pour intégrer le markdown il fallait déjà pouvoir le parser et reconnaître les différentes balises utilisées. Pour cela nous avons utilisé flexe marque mais même grâce à cela ça restait très difficile d'identifier certaines balises (notamment les bullets, les liens et checkbox qui sont assez similaires). Une fois cela fait, il a fallu rajouter une surcouche CSS sur notre thème sombre déjà présent. Enfin, nous avons rendu l'édition et le rendu du markdown visible en temps réel ce qui a demandé beaucoup de travail supplémentaire pour l'afficher dynamiquement.
Plugins
Nous voulions dès le départ que le plug-in puisse utiliser les différents services permettant de manipuler notre base de données. Pour cela il, fallait que le plug-in, au moment du chargement, puisse récupérer le contexte de Spring afin que l'injection de dépendance puisse se faire. Le projet a subi des changements majeurs à ce moment-là car il a fallu repenser son architecture pour que cela puisse être possible. Le fait également d'intégrer un plugin en soi sans recompiler le code a été tout un défi.
2. Conclusion
Pour conclure, nous sommes très fiers de cette application. Nous avons fait un pari risqué en voulant combiner différentes technologies ensemble et nous sommes parvenus à en faire ce que nous souhaitions. L'injection de dépendance Spring a été d'une énorme aide et a permis beaucoup de simplification dans l'architecture du code. Même si l'intégration plug-in aurait pu être poussé encore plus, nous sommes épatées d'avoir pu injecter à l'intérieur de celui-ci le contexte de Spring afin de pouvoir réutiliser l'injection de dépendance dans ce dernier. Il faut le voir pour le croire mais Spring et Java FX fonctionne plutôt bien ensemble.
Vémock
I. Introduction
1. Contexte
Ce projet annuel se repose énormément sur le comportement des stations, car ce sont elles qui vont recharger les vélos et indique à l'utilisateur ou en prendra.
Puisque la mairie de Paris n'a pas souhaité nous financez pour mettre à disposition des stations dans la ville, il a fallu les simuler nous-mêmes pour avoir un comportement cohérent sur le site.
2. Application choisie
Nous avons développé Vemock pour répondre à ce besoin et simuler le comportement d'une station complètement autonome.
Cette application enverra régulièrement au serveur l'évolution d'une station autonome, à savoir le nombre d'emplacements vélos utilisés, le niveau de batterie, la puissance de charge, etc.
II. Focus sur l’application
1. État d’une station et configuration
Il y aura plusieurs paramètres à simuler dans le cycle de vie d'une borne, à savoir :
· La batterie
· Si la station est active
· La puissance de charge
· Le nombre d'emplacements de vélo utilisé
Ces paramètres doivent suivre une évolution cohérente donc certaines règles ont été mises en place afin d'apporter de la cohérence.
Comportement de la batterie
· Elle doit varier dans un intervalle de 0 à 100%
· Elle se décharge constamment, mais un peu moins la nuit.
· Elle dépend de la puissance de charge de la borne et un petit peu d'aléatoire
· Elle se décharge beaucoup plus vite s'il y a beaucoup de vélos sur la borne
· Si la batterie est en dessous de 15 pour 100, elle se rechargera plus facilement
· Dans le cas où la batterie tombe en dessous de 15 pour 100 et si la configuration le permet, la station passera en statut inactif
Puissance de charge
· Elle dépend d'un peu d'aléatoire
· La puissance de charge est faible le matin, très élevé en journée, puis à nouveau faible le soir.
· La puissance de charge est nulle la nuit
Nombre d’emplacements utilisés
· Le nombre d'emplacements utilisé est un peu aléatoire
· L'évolution du nombre d'emplacements utilisés doit être cohérentes par rapport au précédent état.
Configuration d’une station
Au démarrage, l'application va charger la configuration propre à la borne qu'elle doit simuler, à savoir :
· L'idée de la station
· Si elle a le droit de passer en statut inactif quand la batterie est trop basse
· Le nombre maximum d'emplacements vélo
· Le nom du fichier d'historique pour la reprise
· Le temps d'attente entre chaque envoi de données
· La puissance maximale de charge
· Le token d'authentification auprès du serveur
· Le lien pour accéder au serveur
· Si elle doit afficher des données de débogage pendant son exécution
Si ces données sont mises à jour et que la station redémarre, elle prendra en compte les changements.
2. Persistance de l’état et reprise
Si jamais une station s’éteint (l'application est coupée), elle ne doit pas repartir avec des valeurs initiales lorsqu'elle redémarre, mais bien avec les dernières données générées.
C'est pour cela qu’à chaque nouveau changement de statut de la borne, un fichier historique est mis à jour pour garder en mémoire le dernier statut connu de la borne.
Au démarrage de l'application, si ce fichier n'existe pas, alors l'application prend des valeurs initiales par défaut, sinon elle reprend là où elle s'était arrêtée.
3. Envoie des données
À chaque nouveau changement d’état, une métrique est envoyée sur le serveur API.
Cette requête contient :
· Le token d'autorisation de la borne dans l’en-tête qui permettrait au serveur d'identifier celle-ci
· Le pourcentage de batterie
· La puissance de charge
· Si elle est active
· Le nombre d'emplacements vélo utilisé
Nous utilisons le client HTTP standard fourni par la lib python.
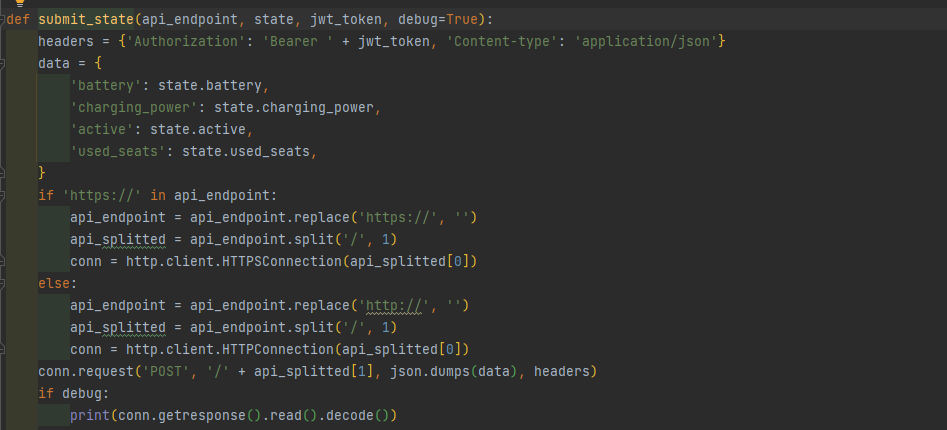
4. Logging des actions
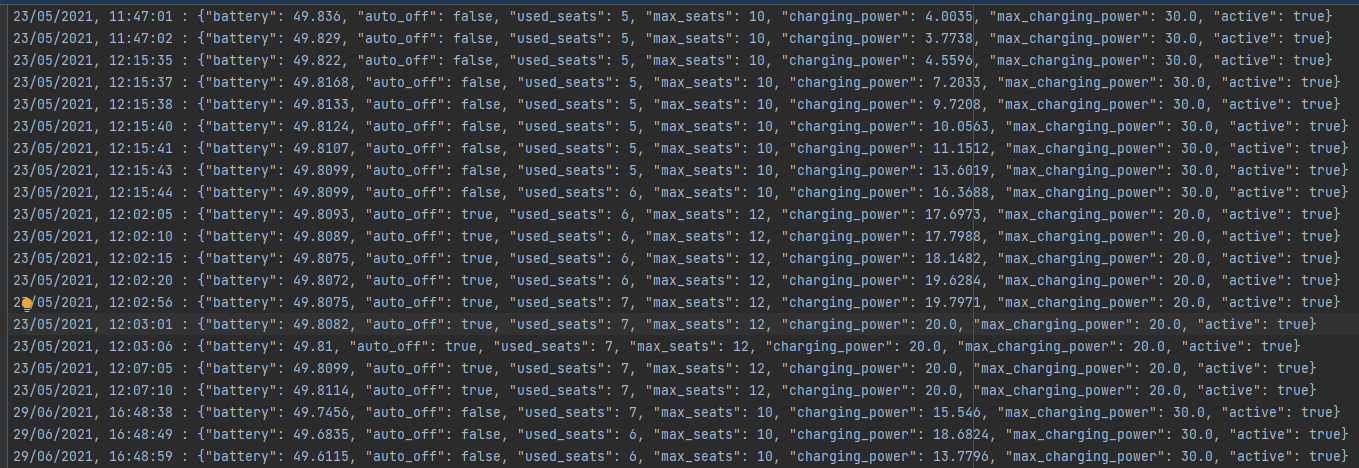
Si les logs sont activés ; à chaque changement d'état de la station ; il sera affiché en compte sol le nouvel état de la station ainsi que la requête envoyée.
Ces données sont également sauvegardées dans un fichier.
5. Générateur du docker-compose
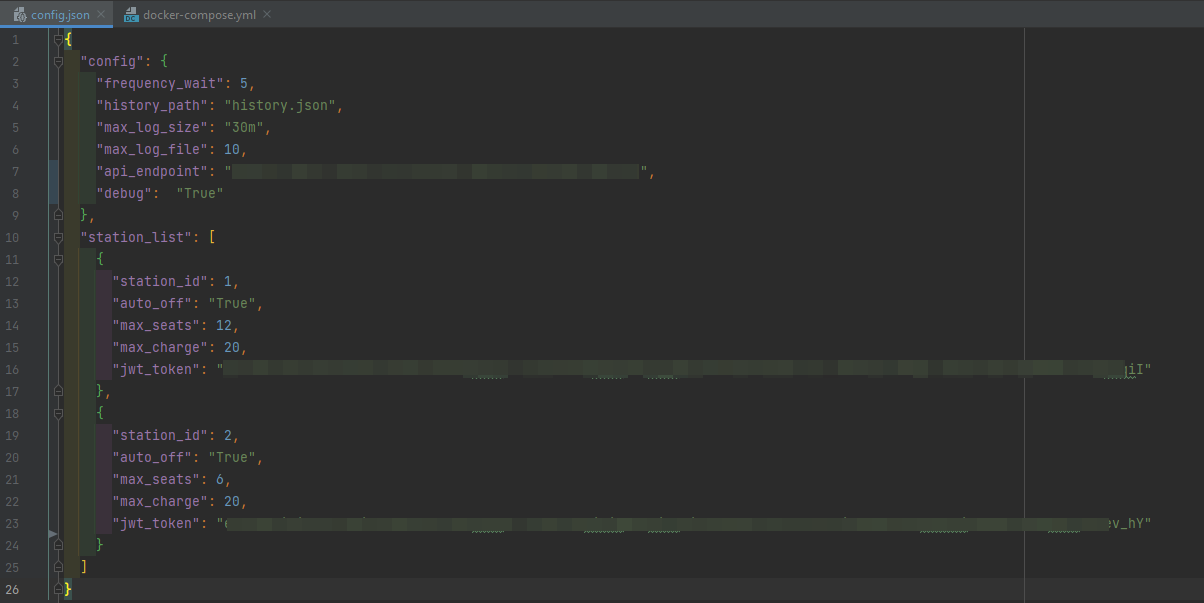
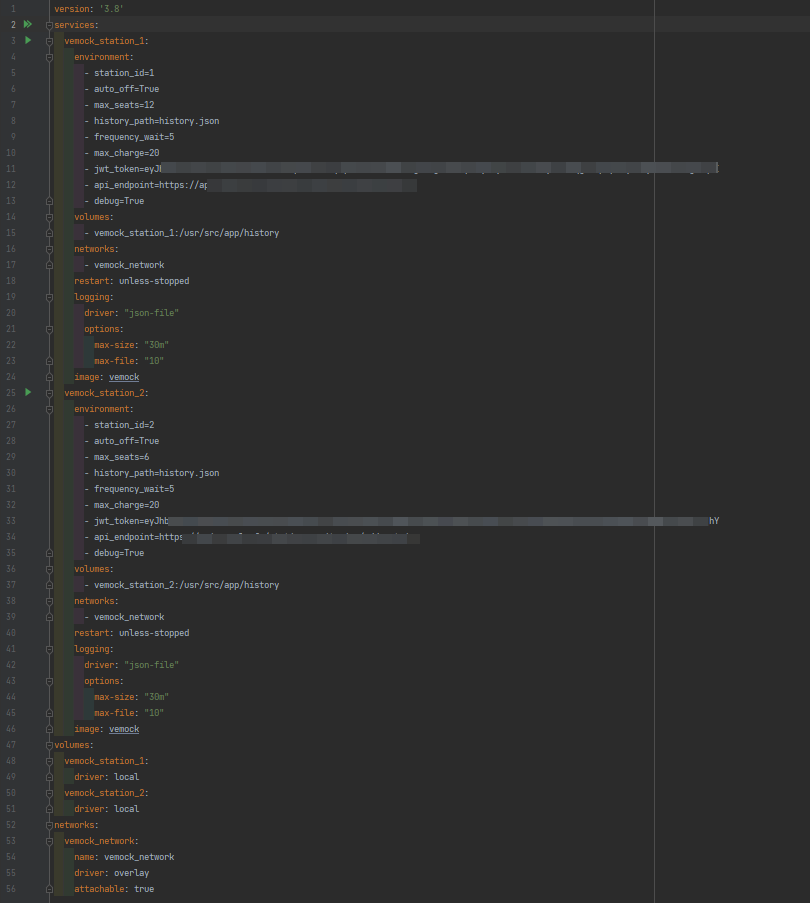
Pour simuler le comportement de 100 stations, le fichier docker compose docker-compose.yml fais plus de 2400 lignes. Bien sûr, il serait trop long d'écrire toutes ces lignes à la main…
Nous avons donc mis au point un script python qui permet à partir d'un fichier de configuration JSON beaucoup moins gros de générer notre docker-compose.yml final.
Voici un exemple des fichiers de configuration avec seulement 2 stations :
III. Choix d’implémentations
1. Langage choisi
| Pour ce projet, nous avons choisi d'utiliser le langage python, car c'est selon nous celui qui répondait le mieux à notre besoin. Il possède beaucoup de librairies permettant de parser et traiter des données, ce qui nous a permis d'aller relativement vite. |  |
2. Contrainte de performance
Puisque cette application est destinée à tourner en plusieurs exemplaires sur un Raspberry, il faut que celui-ci soit le moins gourmand possible.
C'est pourquoi nous n'utilisons pas de librairies externes, mis à part dotenv dans l’environnement de développement.
Avec toutes les optimisations faites, l'application ne prend pas plus de 10 Mo de mémoire vive pendant son exécution.
IV. Bilan du projet
1. Problèmes rencontrés
Librairie Requests trop lourde
Au tout début, nous n’utilisions pas le client natif python, mais une librairie se nomment Requests.
Lors de l'exécution de l'application, nous constations que celle-ci prenait énormément de mémoire. Après beaucoup de vérifications, nous avons découvert que cela venait de cette librairie lorsqu'elle était importée.
Nous avons donc dû faire un changement pour utiliser plutôt la librairie native de python, qui est un peu plus verbeuse, mais moins consommatrice.
Équilibrage des métriques
L'algorithme définissant l'état de la station n'a pas été parfait du premier coup et nous faisions face à des données qui n'étaient pas cohérentes (batterie toujours à 100%, ne charge nulle, capacité de vélo dépassé …).
L’application a ainsi subi plusieurs évolutions pour que le comportement soit le plus cohérent possible.
Fuites de mémoires sur la durée
En plus de la librairie Requests que nous avons enlevé, nous constations des fuites de mémoire lors de l'exécution prolongée de l'application.
Cela venait du fait qu'à chaque requête où log, l'application gardé en cache certaines données et ne les libérait pas tout de suite.
Afin de garder une consommation de mémoire stable, nous manipulons manuellement le Garbage Collector de python pour le forcer à se vider à chaque changement d'état.
2. Conclusion
Bien que ce projet ne soit absolument pas demandé à la base, il était essentiel par rapport au sujet que nous avons choisi.
Nous étions totalement dans l'inconnu lorsque nous avons développé cette application et il a fallu recommencer plusieurs fois, car nous n'avons pas compris tout de suite les problèmes que nous avons rencontrés.
Cependant, nous sommes très satisfaits du résultat et il a enrichi énormément le projet final.
VéScrapper
I. Introduction
1. Rappel du sujet
Pour notre projet annuel, il nous a été demandé de concevoir un Micro-Langage.
Ce Micro-Langage doit nous permettre d'extraire du contenu sur internet en rapport avec notre sujet.
2. Application choisie
Nous avons décidé de développer un micro-langage pour remplacer le moteur de recherche Google à la façon d'un langage SQL.
Celui-ci pourra nous aider à récupérer des modèles de vélos, des images et les sites où ils sont vendus un exploitant la recherche avancée de Google.
https://www.astuces-aide-informatique.info/9691/commandes-recherche-avancees-google
II. Focus sur l’application
1. Menu
Lorsque nous lançons l’application (en ligne de commande), nous arrivons sur un menu nous détaillant ce qu’il est possible de faire sur l’application :
Il suffit ensuite de taper la commande spéciale, ou la requête désirée pour lancer une action.
2. Mode débogage
Le mode débogage permet de visualiser l'arbre de décision de notre requête grâce à la génération d'un fichier PDF.
Cet arbre (sous la forme de tuples) sera également affiché dans la console.
Pour utiliser le mode débogage, il faut obligatoirement avoir installé graphviz sur sa machine.
3. Exemples de requêtes
Il est possible de taper différents types de requêtes afin de trouver des liens ayant du contenu, des images, ou les 2.
On doit spécifier quel est le produit que l'on recherche et sur quel site on veut récupérer les résultats.
Il est possible aussi d'ajouter des mots-clés avec des opérateurs booléens.
Enfin, on peut spécifier la limite du nombre de résultats qui par défaut est à 10.
III. Choix d’implémentations
1. Langage choisi
Pour ce projet, nous avons choisi d'utiliser le langage python, car c'est selon nous celui qui répondait le mieux à notre besoin. Il possède beaucoup de librairies permettant de parser et traiter des arbres de décision, ce qui nous a permis d'aller relativement vite.
2. Technologies et librairies principales utilisées
Afin de passer correctement nos requêtes pour le langage, il a fallu utiliser différentes librairies dont 2 principales.
Ply
Pli est un outil d'analyse écrit uniquement en python il s'agit d'une ré implémentation de Lex Yacc à l'origine en langage c.
Lex : Générateur d’analyseur lexical.
· Prends en entrée la définition des unités lexicales
· Produit un automate fini minimal permettant de reconnaître les unités lexicales
Yacc : Générateur d’analyseur syntaxique.
· Prends en entrée la définition d'un schéma de traduction (produit par Lex)
· Produit un analyseur syntaxique pour le schéma de traduction.
Graphviz
Graphviz est un logiciel de visualisation graphique open source. La visualisation de graphes est un moyen de représenter des informations structurelles sous forme de diagrammes, de graphes abstraits et de réseaux.
Il a des applications importantes dans les réseaux, la bio-informatique, le génie logiciel, la conception de bases de données et de sites Web, l'apprentissage automatique et les interfaces visuelles pour d'autres domaines techniques.
Dans notre cas, il est utilisé dans le mode débogage pour visualiser notre arbre de décision générée par Ply.
IV. Bilan du projet
1. Problèmes rencontrés
Construction de la requête Google
N'ayant pas trouvé de documentation officielle de Google sur toutes les requêtes avancées possibles, il a fallu chercher sur des forums et essayer nous-mêmes différentes combinaisons avant de trouver celle qui fonctionnait le mieux.
Il fallait donc adapter le langage aux combinaisons possibles pour que cela fonctionne.
Théorie d’un langage de programmation
Même si nous avons eu des cours cette année, la théorie des langages reste un domaine que nous ne maîtrisons difficilement dans le groupe et il a fallu redoubler d'efforts pour arriver à créer un nouveau langage.
2. Conclusion
Pour conclure, cette application a été difficile à réaliser par la complexité de ce qu’est un langage de programmation que par le fait de trouver une idée concrète qui puisse venir enrichir le projet de base. L’application finale nous a tout de même été très utile au moment du remplissage de la base de données, car elle nous a permis de trouver très rapidement des modèles de vélo électrique ainsi que des images associées