
Reinforced Frog
Jumper Frog (Frogger Game) in python with AI reinforcement 🐸
 |
 |
Présentation du jeu et Objectif
L'objectif principal est de faire apprendre par renforcement un agent sur le jeu Frogger.
Contexte
Ce projet a été réalisé dans le cadre du cours d'apprentissage par renforcement. Il a été réalisé par 3 étudiants en 5ᵉ année d'architecture logicielle.
Jeu original
| Règle du jeu |
Image du jeu original |
| Frogger est un jeu d'arcade classique. Le but du jeu est de diriger des grenouilles jusqu'à leurs maisons. Pour cela, le joueur doit d'abord traverser une route en évitant des voitures qui roulent à différentes vitesses, puis une rivière aux courants changeants et enfin, à nouveaux, une route. La grenouille meurt si elle touche une voiture ou si elle tombe dans la rivière. |  |
Objectif
L'objectif est de faire apprendre à un agent à traverser la route et la rivière en évitant les voitures et l'eau.
Pour cela, nous allons utiliser l'algorithme Q-Learning. L'agent va apprendre à traverser la route et la rivière en apprenant à associer une action à un état. L'agent va donc découvrir comment associer une action à un état.
Pour cela, nous allons également devoir développer le jeu Frogger en utilisant la librairie arcade. Le seul langage utilisé est le Python, nous n'utilisons pas de librairie externe mis à part arcade et quelques librairies utilitaires.
Installation
Prérequis
- Python 3.10 minimum
- PIP3
Installation des dépendances
Après avoir cloné le projet, il faut installer les dépendances avec la commande suivante :
pip3 install -r requirements.txtUtilisation
Environnement
Avant de lancer le jeu, il faut créer le fichier .env à la racine du projet. Ce fichier contient les variables d'environnement nécessaire au bon fonctionnement du jeu. Vous pouvez vous baser sur le fichier .env.example pour créer le fichier .env.
| Variable |
Description |
Valeur conseillée |
AGENT_COUNT |
Nombre d'agents en simultané sur la carte | 1-10 |
AGENT_DEBUG |
Afficher les informations debugs en console des agents (WIN/LOOSE) | false |
ARCADE_INSIGHTS |
Afficher les informations de l'agent sur le jeu arcade |
true |
AGENT_GAMMA |
Taux de prise en compte de l'état futur | 0.1 |
AGENT_LEARNING_FILE |
Emplacement du fichier qtable | qtable/nom-du-fichier.xz |
AGENT_LEARNING_RATE |
Taux d'apprentissage de l'agent | 0.6 |
AGENT_VISIBLE_COLS_ARROUND |
Nombre de colonnes visible autour de l'agent dans son environnement | 4-6 |
AGENT_VISIBLE_LINES_ABOVE |
Nombre de lignes visible devant l'agent dans son environnement | 1-2 |
EXPLORE_RATE |
Taux d'exploration sur les actions déterminés de l'agent | 0.05-0.1 |
EXPLORE_RATE_DECAY |
Taux de diminution du taux d'exploration | 0.999 |
GENERATE_HISTORY_GRAPH |
Générer le graphique de progression d'apprentissage en même temps que la sauvegarde de la Q-Table | true |
HASH_QTABLE |
Hash des lignes de l'environnement (permet de diminuer un peu la taille en mémoire) | false |
LEARNING_MODE |
Passer en mode apprentissage (console seulement) ou en mode graphique (arcade) | true pour apprendre un peu, puis false |
LEARNING_TYPE |
Type d'apprentissage (QLEARNING, MQLEARNING, DQLEARNING) | QLEARNING-MQLEARNING |
LEARNING_TIME |
Temps de l'apprentissage en minute | 45 |
LEARNING_PRINT_STATS_EVERY |
Afficher en console les stats d'appretissage tous les x secondes | 30-60 |
LEARNING_SAVE_QTABLE_EVERY |
Fréquence de sauvegarde de la Q-Table tous les x secondes (opération lourde) | 60-600 |
QTABLE_HISTORY_FILE |
Emplacement des fichiers d'historique | history/nom-du-fichier.history |
QTABLE_HISTORY_PACKETS |
Paquets pour l'historique | = au nombre d'agents (1-10) |
WORLD_TYPE |
Type de monde ( 0 -> Route + Eau, 1 -> Route seulement, 2 -> Eau uniquement) | 0 |
Pour lancer le jeu, il faut lancer la commande suivante :
python3 main.pyDéveloppement du jeu
Présentation de la librairie arcade
Arcade est une librairie Python permettant de créer des jeux vidéo. Elle est basée sur Pyglet et permet de créer des jeux vidéo 2D. Elle permet de créer des jeux vidéo en 2D avec des sprites, des animations, des sons, des effets de particules…,

Configuration des règles
Afin de pouvoir modifier rapidement la configuration de notre jeu (difficulté, tokens, actions possibles…,), nous avons écrit toute la configuration dans le fichier config.py. Ce fichier est lu par le jeu.
Tokens
Ce fichier de configuration contient les différents tokens utilisés dans le jeu. Ces derniers permettent au jeu d'avoir une représentation textuelle de son environement, ce qui va grandement nous aider pour l'apprentissage de l'agent.
CAR_TOKEN = 'C'
TRUCK_TOKEN = 'Z'
TURTLE_TOKEN = 'T'
TURTLE_L_TOKEN = 'TL'
TURTLE_XL_TOKEN = 'TXL'
REVERSED_CAR_TOKEN = 'RC'
REVERSED_TRUCK_TOKEN = 'RZ'
REVERSED_TURTLE_TOKEN = 'RT'
REVERSED_TURTLE_L_TOKEN = 'RTL'
...
ACTION_UP = 'U'
ACTION_DOWN = 'D'
ACTION_LEFT = 'L'
ACTION_RIGHT = 'R'
ACTION_NONE = 'N'
...
WATER_COMMONS_TOKENS = [TURTLE_TOKEN, TURTLE_L_TOKEN, TURTLE_XL_TOKEN, REVERSED_TURTLE_TOKEN, REVERSED_TURTLE_L_TOKEN,
...]
...
WIN_STATES = [EXIT_TOKEN]Arcade
Ce fichier de configuration contient les différents paramètres de la librairie arcade. Ces derniers permettent de définir les sprites des différentes entités, ainsi que leur taille et le scaling.
SCALE = 1
SPRITE_SIZE = 64 * SCALE
...
def get_sprite_resources(name: str, sprite_size: float = 0.5):
return arcade.Sprite(f":resources:images/{name}.png", sprite_size * SCALE)
def get_sprite_local(name: str, sprite_size: float = 0.5):
return arcade.Sprite(f"assets/sprite/{name}.png", sprite_size * SCALE)
ENTITIES: Dict[str, WorldEntity] = {
CAR_TOKEN: WorldEntity(1, 1, CAR_TOKEN, get_sprite_local("car_1", 0.65)),
...
}
...
WORLD_WIDTH = 180
WORLD_HEIGHT = 117
WORLD_SCALING = 9Représentation du monde
Le monde est représenté par une matrice de caractères. Chaque caractère représente une entité du monde. Les entités sont représentées par des tokens. Ces derniers sont définis dans le fichier de configuration.
La classe permettant de représenter le monde est la classe World. Cette classe permet de
Cette dernière permet de :
- Créer un monde, avec la bonne configuration
- Gérer la mise à jour (déplacement) des entités dans le monde
- Gérer les collisions entre les entités
- Gérer les mouvements, récompenses des joueurs
Représentation du monde pour l'agent
À chaque état, l'agent reçoit une représentation du monde sous forme de liste de chaîne caractères. Chaque élément représente une ligne visible (définit dans les variables d'environnement) du monde.
Ainsi, l'agent ne voit pas toute la carte, mais tout au plus 2 ligne devant lui, 1 ligne derrière lui, et 4 colonnes sur les côtés.
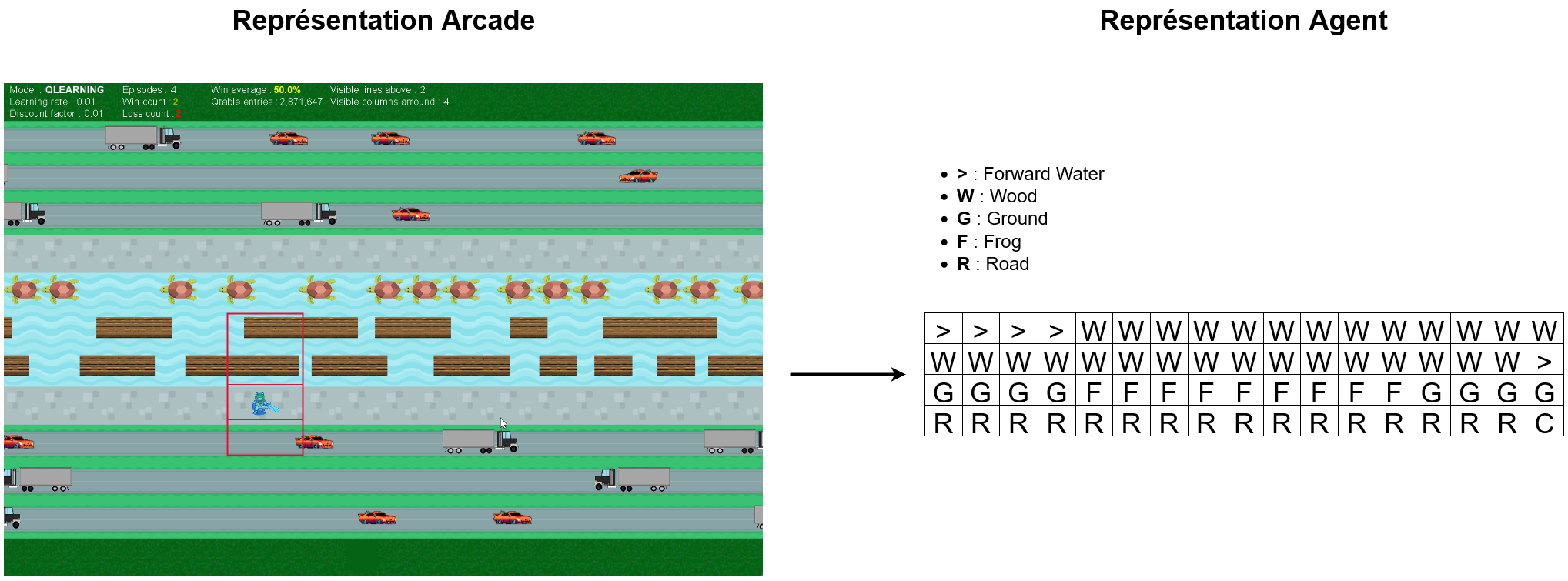
World Entity
Pour généraliser les différentes entités que nous traitons, nous avons la classe WorldEntity. Cette dernière permet de regrouper pour chaque entité :
- La taille de l'entité
- Le token de l'entité
- Le sprite de l'entité
World Line
La classe WorldLine permet de représenter une ligne du monde. Cette dernière permet de gérer les déplacements des entités sur chaque ligne, ainsi que leur fréquence d'apparition, vitesse…,
Joueurs
Le joueur est représenté par l'interface Player. Cette dernière permet de gérer le déplacement du joueur, de le gérer dans la classe principale Game. Cette interface nous permet de gérer plusieurs types de joueurs ( Humain, Agent).
from typing import Tuple, List
from arcade import Sprite
from display.entity.world_entity import WorldEntity
from game.world import World
class Player:
def init(self, world: World, intial_state: Tuple[int, int], _initial_environment: bytes):
pass
def best_move(self, environment: [str]) -> str:
pass
def step(self, action: str, reward: float, new_state: Tuple[int, int], _environment: List[str]):
pass
def save_score(self):
pass
def update_state(self, new_state, new_environment):
pass
@property
def sprite(self) -> Sprite:
pass
@property
def world_entity(self) -> WorldEntity:
pass
@property
def is_human(self) -> bool:
pass
@property
def score(self) -> int:
pass
@property
def state(self) -> Tuple[int, int]:
passJoueur Humain
Le joueur humain est représenté par la classe HumanPlayer. Cette dernière permet de se déplacer avec les touches directionnelles du clavier.
Affichage graphique
L'affichage graphique est entièrement géré par la classe WorldWindow. Cette dernière permet de gérer l'affichage du monde sur arcade. Elle permet également de gérer la vitesse de jeu, le nombre de frames par seconde, les statistiques affichés…,
import arcade.color
from ai.Model import Model
from conf.config import *
from game.game import Game
class WorldWindow(arcade.Window):
def __init__(self, game: Game, env, model: Model):
super().__init__(
int(game.world.width / WORLD_SCALING * SPRITE_SIZE),
int(game.world.height / WORLD_SCALING * SPRITE_SIZE),
'REINFORCED FROG',
update_rate=1 / 60
)
self.__height = int(game.world.height / WORLD_SCALING * SPRITE_SIZE)
# ...
# ...
def setup(self):
self.setup_world_states()
self.setup_players_states()
self.setup_world_entities_state()
def setup_world_entities_state(self):
self.__entities_sprites = arcade.SpriteList()
for state in self.__game.world.world_entities_states.keys():
world_entity: WorldEntity = self.__game.world.get_world_entity(state)
if world_entity is not None:
sprite = self.__get_entity_sprite(state, world_entity)
self.__entities_sprites.append(sprite)
def setup_world_states(self):
self.__world_sprites = arcade.SpriteList()
for state in self.__game.world.world_states:
world_entity: WorldEntity = self.__game.world.get_world_line_entity(state)
if world_entity is not None:
sprite = self.__get_environment_sprite(state, world_entity)
self.__world_sprites.append(sprite)
def setup_players_states(self):
self.__players_sprites = arcade.SpriteList()
for player in self.__game.players:
sprite = player.sprite
sprite.center_x, sprite.center_y = (
self.__get_xy_state((player.state[0] + WORLD_SCALING // 2, player.state[1] + WORLD_SCALING // 2)))
self.__players_sprites.append(sprite)
def __draw_debug(self):
# ...
def on_draw(self):
arcade.start_render()
self.__world_sprites.draw()
self.__entities_sprites.draw()
self.__players_sprites.draw()
if self.__debug == 1:
self.__draw_debug()
elif self.__debug == 2:
self.__draw_collisions_debug()
if self.__env['ARCADE_INSIGHTS']:
self.__draw_model_insights()
def __draw_model_insights(self):
# ...
def on_update(self, delta_time: float):
self.__game.step()
self.setup_players_states()
self.__players_sprites.update()
self.setup_world_entities_state()
self.__entities_sprites.update()
# ...Développement de l'IA
Pour l'IA, nous avons utilisé 3 méthodes principales :
- Q-Learning
- Multi-Q-Learning
- Deep Q-Learning
Q-Learning
Le Q-Learning est une méthode d'apprentissage par renforcement. Cette méthode permet de déterminer la meilleure action à effectuer dans un état donné. Pour cela, elle utilise une fonction de valeur Q qui permet de déterminer la valeur d'une action dans un état donné. Cette fonction est mise à jour à chaque étape de l'apprentissage.
Implémentation
L'implémentation du Q-Learning est géré par la classe QLearning. Cette dernière permet de gérer la table de Q-Learning, de mettre à jour les valeurs de la table, de récupérer la meilleure action à effectuer, de sauvegarder la table de Q-Learning, ...
Cette classe permet également (comme les autres méthodes d'apprentissage) de gérer l'exploration et l'exploitation, ainsi que l'historique de progression.
Nous nous basons sur l'équation de Bellman pour mettre à jour la table de Q-Learning :
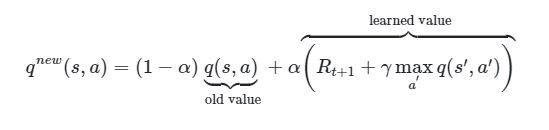
La Qtable est formé sous forme de dictionnaire récursif de N+1 dimension, N étant le nombre total de lignes visible. L'idée est de fusionner ensemble les clés communes afin de ne pas consommer trop de mémoire vive (on peut avoir plus de 5 millions de clés différentes). La première dimension représente la première ligne visible, la deuxième dimension la seconde…, La dernière dimension représente les actions possibles.